
自适应大模型的创新突破
随着人工智能技术的快速发展,自适应大模型(Adaptive Large Language Models, LLM)逐渐成为研究的热点。Sakana AI发布的Transformer²框架,为自适应大模型的发展带来了全新的突破。该框架借鉴了章鱼根据环境变色的能力,使模型能够根据不同的任务和环境动态调整自身行为。这种动态调整不仅提高了模型的适应性,还大大降低了计算成本。
Transformer²的核心思想
Transformer²的核心思想在于让模型能够自主评估并修改自身行为,以适应运行环境的变化。这一过程分为两步:首先,模型接收用户查询并识别任务类型;其次,模型根据识别出的任务动态更新权重,生成特定任务的输出结果。这种两步处理策略使得模型能够在不同的任务中表现出色,无论是数学推理还是语言处理。
奇异值分解在微调中的应用
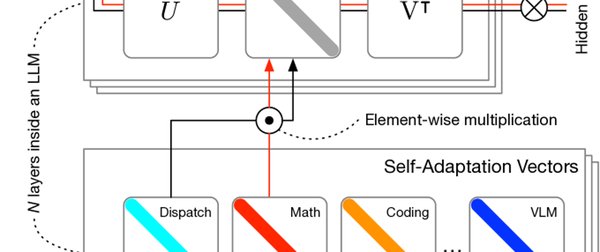
在微调技术方面,Transformer²采用了奇异值分解(SVD)方法。SVD将神经网络的权重矩阵分解为三个部分:U、Σ(对角矩阵)和 Vᵀ。通过修改对角矩阵 Σ 中的值,模型无需重新训练整个网络,就能实现对权重的精细调控。这种方法不仅减少了可训练参数的数量,还增强了模型的表达能力,为Fine-tuning提供了新的可能性。

多模态自然语言处理的实际应用
在成都新增的3款大模型中,行者AI多模态大模型展示了多模态自然语言处理技术的强大潜力。该模型由成都潜在人工智能科技有限公司开发,涵盖了多模态自然语言处理、数字文娱产业以及政企行业智能化转型等领域。通过前沿技术的支持,如RAG和半监督学习技术,这些模型能够显著提升企业和用户的智能化体验。
样本级模块选择的优势
Transformer²框架中的样本级模块选择策略,使得模型能够综合考量整个输入样本,再将其发送到相关模块处理。这种策略与传统的令牌级策略相比,更加灵活和高效。例如,在处理“What is the weather like today?”这样的问题时,模型会先评估整个问题,再将其发送到语言模块处理,从而提高了处理的准确性和效率。

Fine-tuning的未来展望
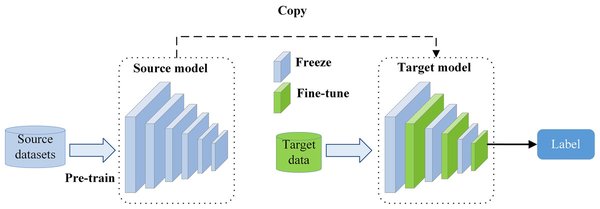
随着自适应大模型和微调技术的不断进步,Fine-tuning在未来将发挥更加重要的作用。通过奇异值分解和样本级模块选择策略,模型能够在极小的计算成本下,动态适应各类任务。这种方法不仅提升了性能,还降低了过拟合风险,为实际应用带来了广阔前景。
技术挑战与解决方案
尽管自适应大模型和微调技术取得了显著进展,但仍面临一些技术挑战。例如,如何在不增加计算成本的情况下,进一步提高模型的适应性;如何在有限的数据下,实现更高效的微调。针对这些问题,未来的研究可以探索更多的创新方法,如混合专家模型(MoE)和基于强化学习的微调技术。
总结
自适应大模型和微调技术的结合,为人工智能的发展开辟了新的道路。Transformer²框架的创新之处在于其动态调整能力和高效的微调方法,为实际应用提供了强大的支持。随着技术的不断进步,Fine-tuning将在未来的智能化系统中发挥更加重要的作用,推动人工智能技术的广泛应用。





