稀疏专家混合模型(MoE)的核心原理
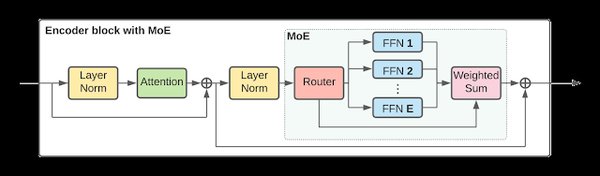
稀疏专家混合模型(Mixture-of-Experts, MoE)是一种高效的计算架构,旨在解决大模型训练和推理中的计算开销问题。其核心思想是通过引入多个子网络(即“专家”),在每次前向传播时仅激活部分子网络,从而减少计算量。这种稀疏激活技术不仅提高了计算效率,还保持了模型的高性能。
MoE在大模型中的应用
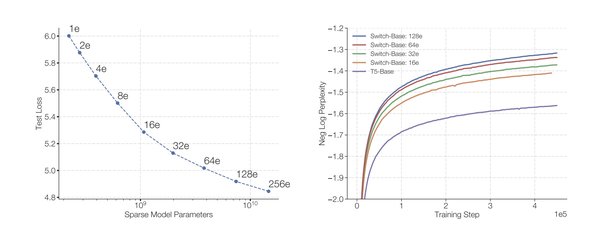
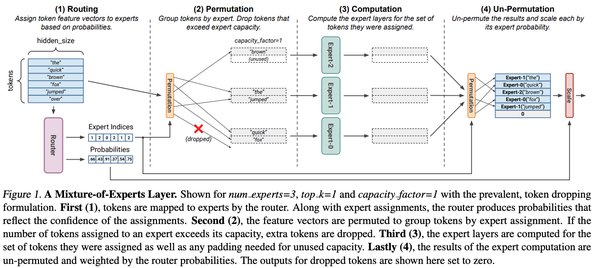
谷歌提出的Switch Transformer模型是MoE架构的典型代表。该模型在多个自然语言处理(NLP)任务中表现优异,同时显著降低了计算开销。Switch Transformer通过动态路由机制,将输入数据分配给最合适的专家网络,从而实现了计算资源的高效利用。


开源实现与开发者支持
为了方便开发者将MoE技术应用到自己的大模型中,GitHub上已有许多开源实现。例如,Fairseq框架中的MoE模块为开发者提供了便捷的工具,支持稀疏激活技术的快速集成。这些开源资源为MoE的普及和推广提供了重要支持。
MoE的未来发展
随着人工智能大模型的快速发展,MoE架构在计算效率和性能优化方面的优势将更加突出。未来,MoE有望在更多领域得到应用,例如计算机视觉、语音识别等。同时,研究者们也在探索如何进一步优化MoE的动态路由机制,以提升模型的稳定性和泛化能力。
稀疏专家混合模型(MoE)作为一种高效的计算架构,正在为人工智能大模型的发展注入新的活力。通过稀疏激活技术,MoE不仅提升了计算效率,还为模型的性能优化提供了新的思路。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...



AI-magic收录了大量国内外AI工具箱,包括AI写作、图像、视频、音频、编程等各类AI工具,以及常用的AI学习、技术、和模型等信息,让你轻松加入人工智能浪潮。