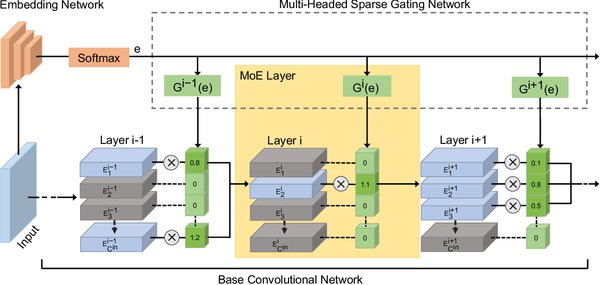
稀疏专家混合模型(MoE)的技术原理
稀疏专家混合模型(Mixture of Experts, MoE)是一种创新的深度学习架构,旨在通过引入多个“专家”子网络来提升模型的效率和性能。与传统的Transformer模型不同,MoE模型在每次前向传播时仅激活部分子网络,从而显著降低了计算开销。
MoE的核心机制包括:
-
专家网络:每个专家是一个独立的神经网络,负责处理特定类型的输入。
-
门控机制:通过稀疏门控(Sparse Gating)机制,模型根据输入选择最相关的专家网络进行激活。
-
并行计算:专家网络可以在分布式系统中并行运行,进一步提升了计算效率。
谷歌在MoE领域的研究处于领先地位,其Switch Transformer模型通过MoE架构在多个自然语言处理(NLP)任务中展现了卓越性能,同时大幅降低了计算成本。

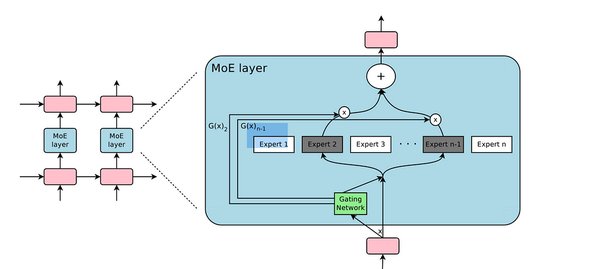
MoE在谷歌Gemini 1.5 Pro中的应用
谷歌最新推出的Gemini 1.5 Pro模型正是基于MoE架构的典范。Gemini 1.5 Pro不仅继承了MoE的高效特性,还在多模态任务中展现了突破性进展。以下是其核心亮点:
-
超大上下文窗口:Gemini 1.5 Pro支持高达100万个token的上下文窗口,能够一次性处理1小时视频、11小时音频或超过30,000行代码。
-
多模态理解:该模型能够无缝分析文本、图像、音频和视频,例如从44分钟的无声电影中推理出复杂的情节点。
-
上下文学习:Gemini 1.5 Pro具备强大的上下文学习能力,能够从长提示中学习新技能,例如将英语翻译成全球使用人数不足200人的卡拉芒语。
这些特性使得Gemini 1.5 Pro成为当前最先进的多模态大模型之一,为人工智能的应用开辟了新的可能性。

MoE的优势与挑战
MoE架构的主要优势包括:
-
高效计算:通过稀疏激活机制,MoE显著降低了计算资源需求。
-
可扩展性:MoE可以轻松扩展到成百上千个专家网络,适用于超大规模数据集。
-
多任务适配:MoE适用于多种任务,包括自然语言处理、计算机视觉和多模态学习。
然而,MoE也面临一些挑战:
-
门控机制优化:如何设计更高效的门控机制以精确选择专家网络仍是一个研究热点。
-
训练复杂性:大规模MoE模型的训练需要复杂的分布式计算框架。
-
硬件适配:MoE的高效运行依赖于特定的硬件支持,例如GPU集群。
MoE的未来展望
随着人工智能技术的不断发展,MoE架构有望在更多领域展现其潜力。例如:
-
多模态融合:MoE可以进一步整合文本、图像、音频和视频信息,推动跨模态理解和生成任务的发展。
-
个性化应用:通过定制化专家网络,MoE可以为用户提供更个性化的服务,例如智能助手和推荐系统。
-
开源生态:谷歌等科技巨头已将MoE技术开源,为研究者和开发者提供了探索和改进的平台。
稀疏专家混合模型(MoE)正在成为人工智能大模型的高效引擎,其创新架构和广泛应用将为AI技术的发展注入新的活力。





