
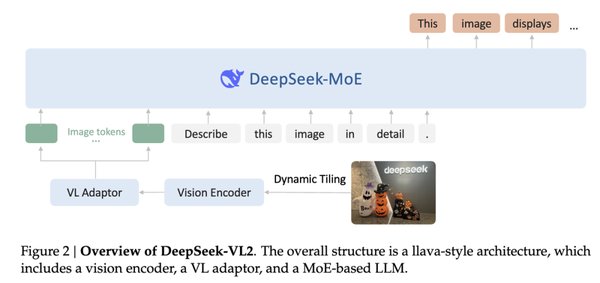
DeepSeek VL 的技术突破
DeepSeek VL 是 DeepSeek 在多模态视觉语言模型领域的重要创新。它基于 DeepSeek-LLM-1.3B-base 模型,经过 500 亿文本令牌和 400 亿视觉语言令牌的训练,具备强大的多模态理解能力。其独特的高分辨率 SAM-B 视觉编码器能够将图像调整至 1024 x 1024 分辨率,生成 64 x 64 x 256 的特征图,并通过卷积层进一步优化,最终输出 576 x 1024 的特征图。低分辨率的 SigLIP-L 视觉编码器也采用相似流程,确保模型在不同分辨率下的高效表现。
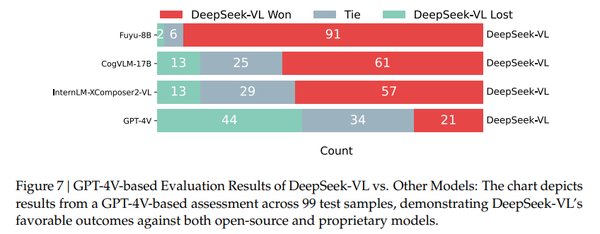

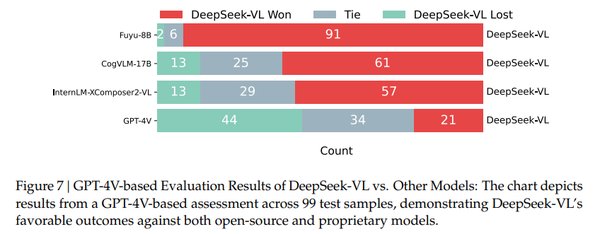
性能评测:超越竞争对手
在人工评测的 99 个测试样本中,DeepSeek VL 与 GPT-4V 及其他开源多模态模型(如 Fuyu-8B、CogVLM 和 InterLM)进行了对比。结果显示,DeepSeek VL 在超过 60% 的案例中被评价为更优,展现了其在多模态理解任务中的卓越性能。此外,与 GPT-4V 和 Qwen 等专有模型相比,DeepSeek VL 同样表现出了匹敌的出色性能,成为多模态领域的有力竞争者。
应用场景与未来发展
DeepSeek VL 的高效性和强大性能使其在多个领域具有广泛的应用潜力:
-
图像理解与生成:能够处理高分辨率图像,适用于图像标注、视觉问答等任务。
-
多模态推理:结合文本与视觉信息,支持复杂的推理任务,如科学问题解答和逻辑推理。
-
跨语言翻译:通过多模态理解,提升翻译工具的准确性和上下文感知能力。
未来,DeepSeek VL 的进一步优化将推动多模态模型在更多场景中的应用,为 AI 技术的发展提供更强大的支持。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...






AI-magic收录了大量国内外AI工具箱,包括AI写作、图像、视频、音频、编程等各类AI工具,以及常用的AI学习、技术、和模型等信息,让你轻松加入人工智能浪潮。