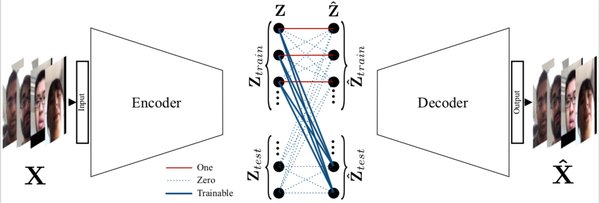
稀疏自动编码器(SAE)简介
稀疏自动编码器(Sparse AutoEncoder, SAE)是一种在自动编码器基础上引入稀疏性约束的技术。其核心目标是通过限制中间层的激活状态,使模型能够学习到数据的稀疏表征。与传统自编码器相比,SAE不仅能够有效压缩数据,还能提取更具解释性的特征。

SAE的工作原理
SAE通过在损失函数中添加稀疏性惩罚项(如L1正则化),迫使模型在编码过程中生成稀疏的中间表示。这种稀疏性约束使得模型能够更专注于数据的关键特征,而非冗余信息。例如,在GPT-3等大型语言模型中,SAE被用于分解复杂的中间激活,从而揭示模型内部的逻辑结构。
SAE的应用场景
-
轻量级模型设计:通过引入稀疏性约束,SAE能够显著减少模型的参数量,提高推理效率,特别适用于移动设备和物联网设备。
-
特征提取:SAE在图像处理、自然语言处理等领域中,被广泛用于提取高级语义表示。
SAE的技术挑战与解决方案
尽管SAE在模型解释和效率方面表现出色,但其仍面临一些挑战:
-
评估难题:由于缺乏明确的底层真实值,SAE的可解释性评估往往依赖于主观判断。
-
稀疏性与准确性的权衡:过度稀疏化可能导致重建精度下降,因此需要在稀疏性和重建准确性之间找到平衡。
-
计算复杂度:SAE的训练和推理过程需要较高的计算资源,研究者正在探索更高效的算法,如SHAP-SAE。
SHAP-SAE:稀疏性与可解释性的结合
SHAP-SAE是一种基于Shapley值的稀疏自动编码器算法,能够显式地测量模型中各单元和链路的重要性。通过选择性地激活重要单元,SHAP-SAE在保持高稀疏性的同时,显著提升了模型的可解释性和鲁棒性。实验表明,SHAP-SAE在多种数据集上均优于传统的密集自编码器。
未来展望
稀疏自动编码器作为深度学习领域的一项重要技术,正在推动模型可解释性和效率的边界。随着研究的深入,SAE有望成为机器学习模型的“MRI”,为模型内部机制提供更清晰的洞察。未来,结合更多先进算法和优化技术,SAE将在更多实际应用中发挥关键作用。
通过本文的探讨,我们不难发现,稀疏自动编码器不仅是一种技术工具,更是连接深度学习模型与人类理解的重要桥梁。随着SAE技术的不断发展,我们有理由相信,未来的深度学习模型将更加透明、高效且易于解释。






