
引言:AI推理效率的新范式
在人工智能领域,推理效率一直是制约大模型广泛应用的关键瓶颈。DeepSeek公司通过其创新的稀疏激活架构,成功突破了这一限制,重新定义了AI推理的效率与成本平衡。本文将深入探讨稀疏激活架构的核心技术及其在实际应用中的表现。
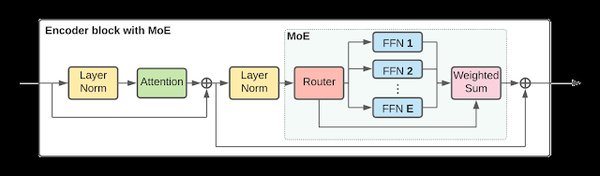
稀疏激活架构的核心技术
混合专家模型(MoE)
DeepSeek的稀疏激活架构核心在于其混合专家模型(MoE)。MoE通过动态路由机制,将输入分配给最相关的专家网络,从而在每次推理时仅激活一小部分参数。这种“稀疏激活”策略显著降低了计算资源和内存消耗,同时保持了模型的高性能表现。
多头潜在注意力(MLA)
多头潜在注意力(MLA)是DeepSeek稀疏激活架构的另一大创新。MLA通过低秩压缩技术,将Key-Value矩阵投影至潜在空间,减少了93%的显存占用。这一技术在处理长序列数据时尤为有效,显著提升了推理速度和资源利用率。
强化学习(RL)
DeepSeek在稀疏激活架构中引入了强化学习技术,通过奖励机制优化模型的推理策略。这种“纯强化学习”方法无需依赖大量标注数据,显著降低了训练成本,同时提升了模型在复杂任务中的表现。

稀疏激活架构的实际应用
数学推理
在数学推理任务中,DeepSeek的稀疏激活架构表现出色。例如,在2024年美国数学邀请赛(AIME)中,DeepSeek-R1模型的通过率@1得分跃升至71.0%,超越了GPT-4等主流模型。
代码生成
在代码生成任务中,DeepSeek的稀疏激活架构同样表现出色。其生成的代码可运行性达到85%,正确率达到70%,显著提升了开发效率。
自然语言处理
在自然语言处理任务中,DeepSeek的稀疏激活架构支持多轮对话与情感分析,准确率超70%。这种高效的自然语言处理能力为智能客服和内容生成等应用场景提供了强大支持。
稀疏激活架构的行业影响
技术范式重构
DeepSeek的稀疏激活架构通过动态MoE和MLA技术,将更多算力转向实时推理,满足了企业级需求。这种技术范式的重构,显著提升了AI应用的普及性和可及性。
生态冲击波
DeepSeek的开源策略催生了开发者社区的爆发式创新。其32B蒸馏版本性能超越GPT-3.5,使边缘设备部署成为可能,进一步推动了AI技术的民主化。
政策与资本关注
DeepSeek的稀疏激活架构引起了全球政策制定者和资本的广泛关注。美国AI领袖Sam Altman评价其“重新定义了开放模型的边界”,中国AI基础设施投资因此增长45%,加速了国产算力布局。
结论:稀疏激活架构的未来
DeepSeek的稀疏激活架构不仅是技术突破,更标志着AI研发从“数据规模竞赛”转向“算法与架构创新”的新纪元。随着MoE与强化学习的进一步融合,AI的“思考”方式将愈发接近人类,而DeepSeek已在这场革命中占据了先机。未来,稀疏激活架构有望在更多领域发挥其潜力,推动AI技术的广泛应用和普及。






