引言
在人工智能领域,缩放定律(Scaling Laws)被视为推动模型性能提升的核心理论。随着计算资源、模型规模和数据量的增加,模型的性能会以可预测的方式持续提升。然而,如何在有限的资源下最大化模型效能,成为当前AI技术发展的关键挑战。DeepSeek作为中国AI产业的代表,通过创新技术和开源生态,不仅验证了缩放定律的有效性,更推动了AI产业的全面变革。
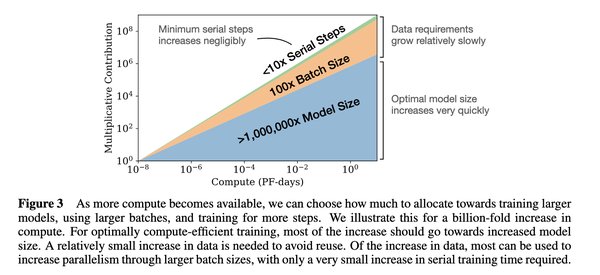
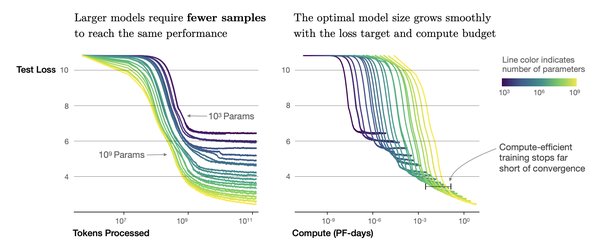
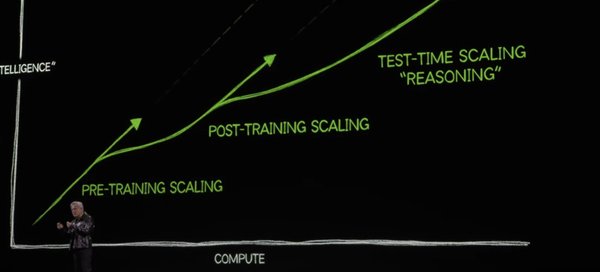
缩放定律的三个阶段
缩放定律的应用贯穿AI模型的全生命周期,通常分为以下三个阶段:
- 预训练阶段:通过大规模数据和计算资源进行模型初始化训练。
- 后训练阶段:利用强化学习等技术对模型进行微调,提升其推理能力。
- 测试时间缩放:在模型推理阶段,通过优化算法和硬件配置实现高效运行。
DeepSeek的R1模型正是“测试时间缩放”的绝佳范例,其在推理任务上的表现与OpenAI的顶尖模型相当,同时大幅降低了成本。
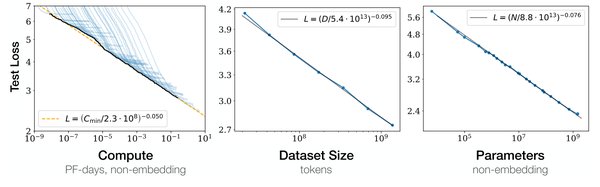
DeepSeek的技术创新与缩放定律
算法创新:MLA与MoE架构
DeepSeek通过引入多头潜在注意力机制(MLA)和混合专家模型(MoE),显著提升了模型的推理效率。MLA通过低秩键值联合压缩技术,减少了KV缓存,降低了内存占用;MoE则通过稀疏激活机制,动态选择专家网络进行计算,大幅提高了推理吞吐量。
强化学习与GRPO算法
DeepSeek采用组相对策略优化(GRPO)算法替代传统的PPO算法,省去了价值模型的计算负担,显著提升了训练效率。这种创新使得DeepSeek能够在低成本下实现与顶尖模型相当的性能。
开源生态与算力平权
DeepSeek的开源策略不仅推动了全球AI开发者生态的繁荣,更通过“算力平权”理念,降低了AI技术的使用门槛。其API定价仅为GPT-4的1/50,引发了行业价格战,加速了AI应用的普及。
DeepSeek对AI产业链的影响
算力需求的结构性变化
随着DeepSeek的高性价比模型推动AI应用的广泛落地,推理算力需求预计将迎来爆炸式增长。推理集群的部署规模从百卡级向千卡级演进,带动了ASIC、光模块、交换机等硬件设备的需求。
下游应用的百花齐放
DeepSeek的低成本模型为AI应用开发者提供了更多可能性,尤其是在AI SaaS、智能终端、垂类模型等领域。例如,情感陪伴型AI应用因成本降低而迅速普及,AI智能硬件也迎来了爆发式增长。
国产芯片的崛起
DeepSeek的成功为国产芯片厂商注入了新动力。华为昇腾、寒武纪等厂商通过与DeepSeek的深度适配,正在改写英伟达的算力垄断格局。
未来展望
随着缩放定律的持续延拓,AI模型的性能将进一步提升。DeepSeek的开源生态和技术创新,不仅为中国AI产业探索了一条差异化发展路径,更为全球AI技术的普及和落地提供了新范式。未来,算力平权、推理优化和应用多元化将成为AI产业发展的关键词。
结语
DeepSeek的崛起不仅是技术创新的胜利,更是开源生态和算力平权理念的成功实践。在缩放定律的指引下,AI技术将迎来更加开放、多元的未来,而DeepSeek无疑将成为这一变革的重要推动者。






