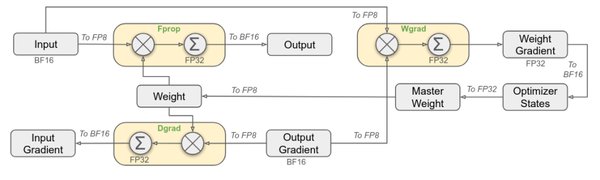
后训练:AI模型优化的关键阶段
在AI模型的开发流程中,后训练(Post-Training)是至关重要的一环。它通过微调和优化基础模型,使其更适应实际任务需求。DeepSeek R1模型在这一领域的创新,正在为AI产业链带来深远影响。
后训练的核心技术
后训练主要包括以下步骤:
1. 指令/对话微调:通过结构化数据集,让模型学会遵循指令、执行任务并遵守安全规范。
2. 领域特定微调:使模型适应医学、法律、编程等特定领域的需求。
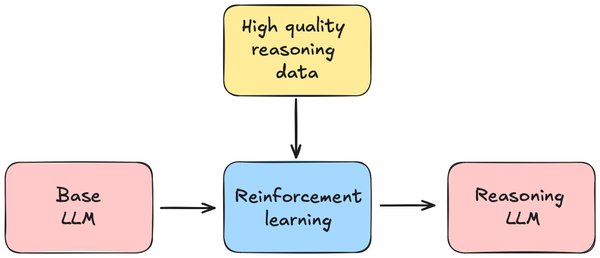
3. 强化学习(RL):通过奖励机制,让模型从自身经验中学习,生成更高质量的响应。
DeepSeek R1模型通过独特的训练方案,如冷启动监督微调和大规模强化学习,显著提升了模型的推理能力和实用性。
后训练对AI基建产业链的影响
GPU与ASIC:需求与挑战并存
DeepSeek R1模型的低算力成本特性,降低了对高性能GPU的依赖,为国产芯片厂商提供了发展机遇。然而,推理算力的需求激增,也推动了英伟达等国际厂商的技术创新。
| 硬件类型 | 影响分析 |
|---|---|
| GPU | 推理需求激增,推动高性能GPU市场增长 |
| ASIC | 国产芯片厂商加速布局,探索更具性价比的部署方案 |
算力市场的短期与长期趋势
- 短期:DeepSeek打破了过去“大力出奇迹”的模型叙事,推动国产算力洗牌,解决了部分智算中心算力闲置的问题。
- 长期:随着AI渗透千行百业,推理算力需求将持续增长,预计未来将向百万卡规模迈进。
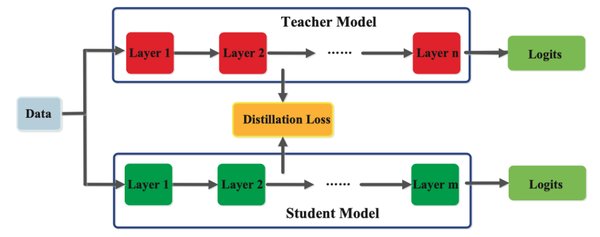

DeepSeek R1模型的技术创新
模型蒸馏与边缘AI
DeepSeek R1模型通过模型蒸馏技术,将大模型的推理能力迁移至更轻量、更快速的模型,降低了智能获取成本。例如,R1模型进行4-bit量化后,仅需450GB总内存,即可在消费级设备上运行。
推理成本的优化
DeepSeek R1模型的推理成本低至0.14美元/百万输入token和2.19美元/百万输出token,显著降低了AI应用的门槛。
AI产业链的机遇与挑战
受益环节
- 云厂商:通过DeepSeek模型加速渗透不同行业,提升云端算力利用率。
- 终端设备厂商:AI PC和智能手机等设备通过端侧部署,实现数据隐私与离线可用性。
- AI Infra厂商:作为连接底层算力与下游应用的中间层,迅速整合生态,推动算力市场洗牌。
潜在挑战
- 算力短缺:长期推理算力需求激增,可能导致资源紧张。
- 技术竞争:国际厂商的技术优势与国产芯片的追赶,将加剧市场竞争。
结语
DeepSeek R1模型的后训练技术,正在为AI基建产业链带来革命性变革。通过降低计算成本、优化推理能力,R1模型推动了AI的广泛采用,并为国产芯片厂商和云服务商提供了新的发展机遇。然而,算力短缺与技术竞争仍是未来需要面对的关键挑战。在这场“算力效率”的游戏中,DeepSeek的创新将引领AI产业迈向新的高度。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...








AI-magic收录了大量国内外AI工具箱,包括AI写作、图像、视频、音频、编程等各类AI工具,以及常用的AI学习、技术、和模型等信息,让你轻松加入人工智能浪潮。