
引言
DeepSeek作为一家杭州的AI初创公司,在2025年1月发布了其开源大型语言模型(LLM),迅速成为全球AI行业的焦点。其推理能力与OpenAI的GPT-4媲美,但训练成本却大幅降低。DeepSeek的成功不仅在于其技术突破,更在于其开源策略,推动了AI模型的普及,并为AI基建产业链带来了新的机遇与挑战。
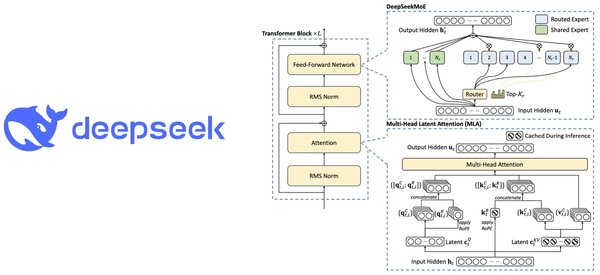
DeepSeek的技术创新
预训练模型的突破
DeepSeek的核心技术之一是其预训练模型DeepSeek-V3-Base。该模型通过大规模文本数据的预训练,学习预测文本序列,为后续的微调和强化学习奠定了坚实基础。预训练模型的成功在于其高效的计算策略和优化的并行配置,例如EP64和TP1的设置,确保了训练过程的稳定性和高效性。
强化学习驱动的推理能力
DeepSeek通过强化学习(RL)技术,成功复现了OpenAI的o1模型的推理能力。其创新点在于:
1. “思考”令牌:引入特殊令牌(如
2. 测试时间计算扩展:模型生成的令牌越多,其推理能力越强。
3. GRPO算法:通过组相对策略优化(GRPO),将奖励信号转化为模型参数的更新,确保训练的稳定性。
DeepSeek-R1-Zero与DeepSeek-R1
DeepSeek-R1-Zero是仅通过强化学习训练的模型,展现了无需监督学习的推理能力。然而,其存在语言混合和可读性差的问题。为解决这一问题,DeepSeek-R1结合了监督微调(SFT)和强化学习,进一步提升了模型的性能和实用性。


DeepSeek对AI基建产业链的影响
高性价比训练技术的市场影响
DeepSeek的训练成本仅为行业巨头的几分之一,但其性能却毫不逊色。这一高性价比的技术为中小企业和研究机构提供了更低的AI模型开发门槛,推动了AI技术的普及。
对硬件基础设施的潜在影响
- GPU与ASIC:DeepSeek的高效训练技术降低了对硬件资源的依赖,可能减缓GPU和ASIC市场的短期增长。
- 光模块与DCI:尽管某些环节面临挑战,但AI基础设施的整体需求仍保持强劲增长。
开源策略与行业变革
DeepSeek的开源策略是其成功的关键。通过MIT开源许可证,DeepSeek的模型权重和训练细节向公众开放,吸引了大量开发者和研究人员的关注。这一策略不仅加速了AI技术的创新,也为行业树立了新的标杆。
结论
DeepSeek通过创新的预训练和强化学习技术,成功复现了OpenAI的o1模型推理能力,并开源了模型权重,推动了AI模型的普及。其高性价比的训练技术为AI基建产业链带来了新的机遇与挑战,预示着AI行业将迎来更广泛的变革与发展。






