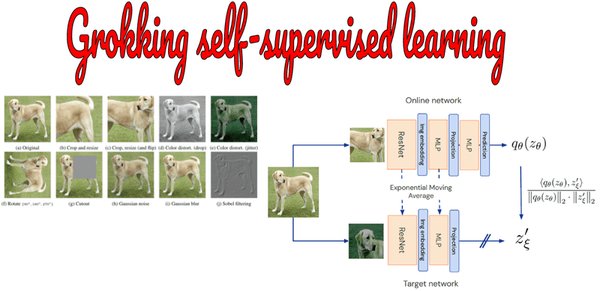
Grokking 现象的理论基础
Grokking 现象是指模型在长时间训练后,突然从过度拟合转变为良好泛化的过程。这一现象可以通过热力学和随机梯度朗之万动力学的概念来解释。具体来说,Grokking 可以被视为从尖锐最小值(记忆)到平坦最小值(泛化)的转变,这一转变由熵最大化驱动。
尖锐最小值与平坦最小值
- 尖锐最小值:模型在训练初期容易陷入的局部最优解,这些解通常对应着过度拟合。
- 平坦最小值:模型在长时间训练后找到的更稳定的解,这些解对应着良好的泛化性能。
熵最大化的作用
熵最大化在避免过度拟合和实现稳健性能中起着关键作用。通过最大化熵,模型能够从记忆数据的状态过渡到泛化数据的状态,从而避免陷入局部最优解。
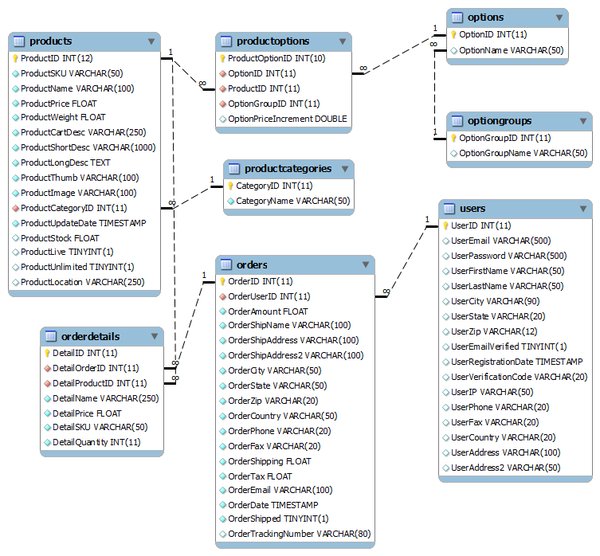
数据库设计中的 Grokking 实践
在实际应用中,Grokking 现象也可以与数据库设计相结合,特别是在设计复杂的系统如电子商务平台时。
数据库设计的基本原则
- 实体与属性的定义:明确系统中的实体及其属性,是数据库设计的第一步。
- 关系的建立:通过建立实体之间的关系,确保数据的完整性和一致性。
- 规范化与优化:通过规范化减少数据冗余,并通过优化提高数据库的性能。
电子商务平台的数据库设计
在设计电子商务平台时,需要考虑多个服务模块的集成,如用户账户、产品目录、购物车、订单处理等。为了确保系统的一致性和可扩展性,可以采用以下策略:
– 数据库事务:确保订单处理的原子性,避免超卖现象。
– 缓存机制:通过缓存产品页面,提高系统的响应速度。
– 队列管理:使用队列管理订单工作流,确保订单在支付失败时不会丢失。

Grokking 时间的定量分析
利用 Eyring 公式,我们可以建立自由能与 Grokking 时间之间的定量联系。这一联系不仅帮助我们理解 Grokking 现象的本质,还为实际应用中的模型训练提供了理论指导。
Eyring 公式的应用
- 自由能与 Grokking 时间:通过 Eyring 公式,可以计算出模型从记忆状态过渡到泛化状态所需的时间。
- 实际应用中的意义:这一定量分析为模型训练提供了时间上的参考,帮助开发者更好地规划训练过程。
总结
Grokking 现象不仅在理论上有其深刻的物理意义,在实际应用中也有着广泛的应用价值。通过理解 Grokking 现象,我们可以在数据库设计、模型训练等多个领域实现更好的性能和更高的效率。无论是设计复杂的电子商务平台,还是优化深度学习模型,Grokking 现象都为我们提供了宝贵的启示。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...









AI-magic收录了大量国内外AI工具箱,包括AI写作、图像、视频、音频、编程等各类AI工具,以及常用的AI学习、技术、和模型等信息,让你轻松加入人工智能浪潮。