深度强化学习与逻辑推理的融合
深度强化学习(DRL)近年来在逻辑推理任务中展现出巨大潜力。Logic-RL框架的提出,标志着DRL在提升大型语言模型(LLM)推理能力方面迈出了重要一步。该框架通过基于规则的强化学习,成功地在7B参数的模型上实现了高级推理能力,如反思、验证和总结。这种能力的提升不仅体现在逻辑谜题的解决上,还扩展到了复杂的数学竞赛题目,如AIME和AMC。
Logic-RL的核心技术
Logic-RL框架的核心技术包括:
-
系统提示(System Prompt):强调模型在思考和回答过程中的细节,确保模型不仅给出答案,还展示详细的思考过程。
-
严格的格式奖励函数(Stringent Format Reward Function):设计奖励函数,惩罚那些走捷径或不按要求输出的模型,防止模型忽略思考过程。
-
简单的训练方法(Straightforward Training Recipe):使用简单但有效的训练方法,确保模型稳定收敛。
强化学习算法的优化
在强化学习算法的选择上,Logic-RL采用了REINFORCE++算法,并进行了关键改进,如引入KL散度作为惩罚项,以防止模型在训练过程中偏离微调模型的策略。这些改进显著提高了训练的稳定性和模型的一致性。
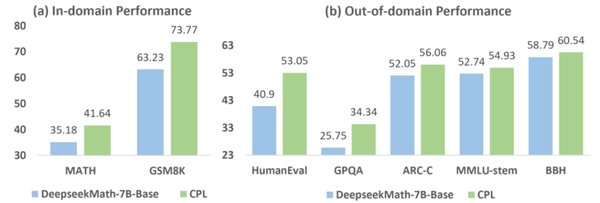
实验结果与泛化能力
经过仅5000个逻辑谜题的训练,7B参数的模型在AIME和AMC等数学推理基准测试中分别提高了125%和38%。这表明模型不仅在训练任务上表现出色,还具备跨领域的泛化能力。
AAAI 2025杰出论文的启示
AAAI 2025杰出论文的发布,进一步展示了DRL在复杂决策任务中的应用。例如,南京大学周志华团队提出的ABL-Refl框架,通过溯因学习改进神经符号AI系统,显著提高了系统的准确性和效率。
多伦多大学的研究贡献
多伦多大学的研究者提出了一种新颖的排序算法,用于多智能体系统中的匹配问题。该算法通过有限数量的基数查询,实现了渐近最优的扭曲界限,显著提高了智能体效率。
未来研究方向
尽管DRL在逻辑推理和复杂决策中取得了显著进展,但仍有许多未解之谜和挑战。未来的研究方向包括:
-
扩展Logic-RL框架到更复杂的任务:如复杂的数学或编程任务,以验证其有效性和鲁棒性。
-
优化强化学习训练过程:探索更高效的训练方法,如课程学习和混合语言推理。
-
探索无约束的推理方法:研究完全无约束或潜在的方法是否能取得更好的效果。
结论
深度强化学习在逻辑推理和复杂决策中的应用前景广阔。通过不断优化算法和框架,DRL有望在更多领域实现突破,为人工智能的发展注入新的活力。








