视觉语言模型的现状与挑战
近年来,大规模预训练视觉语言模型(VLMs)在跨任务迁移学习中展现出强大的能力。然而,当这些模型在有限的少样本数据上进行微调时,往往会出现过拟合问题,导致其在新任务上的性能大幅下降。这一现象凸显了在模型适应性与泛化能力之间寻求平衡的重要性。
多模态表示学习框架的创新
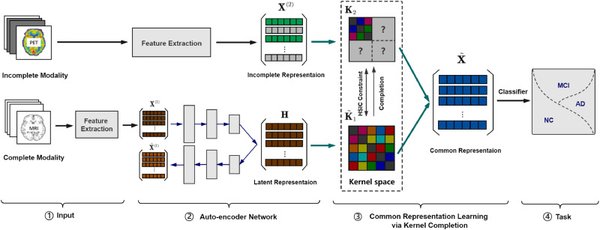
为了解决这一问题,研究人员提出了一种创新的多模态表示学习(MMRL)框架。该框架的核心在于引入了一个共享的、可学习的模态无关表示空间。与以往仅优化类别特征的方法不同,MMRL在编码器的较高层集成表示特征,同时保留较低层的通用知识。具体来说,MMRL通过以下机制实现这一目标:
– 表示特征与类别特征的双重优化:在训练过程中,表示特征和类别特征同时被优化,但类别特征的投影层保持冻结,以保留预训练知识。
– 正则化项引入:通过引入正则化项,将类别特征和文本特征与冻结VLM的零样本特征对齐,从而保护模型的泛化能力。
– 推理阶段的解耦策略:在推理阶段,表示特征和类别特征共同用于基础类别,而仅使用类别特征处理新任务,以确保泛化性能。

实验结果与性能提升
MMRL框架在15个数据集上进行了广泛实验,结果表明其在任务特定适应与泛化能力之间实现了显著平衡。与现有方法相比,MMRL在多个任务上均取得了更优的性能,验证了其有效性和鲁棒性。
未来展望
随着数据集规模的不断扩大,如谷歌DeepMind发布的WebLI-100B数据集,视觉语言模型的性能将进一步提升。MMRL框架的创新为未来研究提供了新的方向,尤其是在处理少样本数据和多模态交互方面。这一领域的持续发展将推动人工智能技术在更广泛场景中的应用。
通过上述分析,我们可以看到,MMRL框架不仅解决了当前视觉语言模型的关键挑战,还为未来的技术进步奠定了坚实基础。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...





AI-magic收录了大量国内外AI工具箱,包括AI写作、图像、视频、音频、编程等各类AI工具,以及常用的AI学习、技术、和模型等信息,让你轻松加入人工智能浪潮。