引言:AI芯片的新纪元
随着大语言模型(LLM)的快速发展,传统的计算硬件在满足其训练和推理需求方面逐渐显现出局限性。GPU虽然在并行计算方面表现出色,但在推理任务中的高功耗和延迟问题仍然存在。为了应对这一挑战,美国AI初创公司Groq推出了一款基于Tensor Streaming Architecture (TSA) 架构的Tensor Streaming Processor (TSP),专为云端大模型推理设计,实现了惊人的推理速度和低功耗。
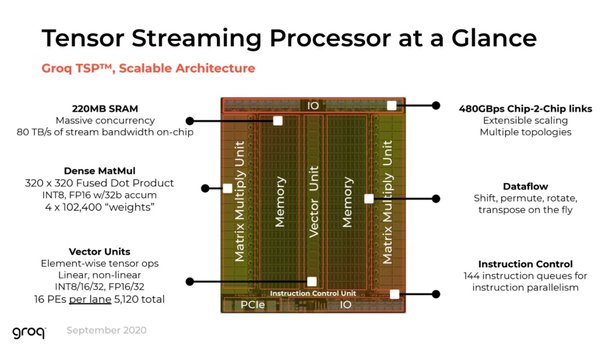
TSP架构的创新设计
超高带宽的SRAM
TSP架构的核心创新之一是其超高带宽的SRAM。Groq LPU配备了230MB的片上SRAM,内存带宽高达80TB/s,是传统GPU HBM带宽的10倍。这种高效的内存架构显著减少了数据传输瓶颈,提升了推理速度。
确定性执行引擎
TSP架构采用了确定性执行引擎,通过VLIW(Very Long Instruction Word)架构,能够精确预知执行时间和顺序,优化了序列处理的性能。这种设计避免了GPU在推理任务中的性能波动问题,提供了稳定的服务质量。
可编程流水线架构
TSP的可编程流水线架构通过高效的片上内存和确定性执行,实现了高吞吐量的数据处理。这种架构特别适合大语言模型的推理任务,能够显著降低延迟,提高推理速度。

TSP在LLM推理中的优势
极高的推理速度
Groq LPU的推理速度远超传统GPU和NPU。例如,在处理Mixtral模型时,Groq LPU每秒可生成500个推理令牌,延迟低至毫秒级,是英伟达GPU的10倍以上。
低功耗与高能效比
TSP架构不仅在性能上表现出色,其功耗也仅为英伟达GPU的1/10。这种低功耗设计使得Groq LPU在高并发推理任务中具有显著的成本优势。
内存访问效率高
TSP架构的内存访问效率高达92%,显著减少了数据传输瓶颈,提升了整体推理性能。
TSP与其他架构的对比
与GPU的对比
| 特性 | GPU | TSP |
|---|---|---|
| 推理速度 | 中等(40-60令牌/秒) | 极高(500令牌/秒) |
| 功耗 | 高(300-700W) | 低(30-70W) |
| 内存带宽 | 3.35TB/s | 80TB/s |
| 确定性执行 | 无 | 有 |
与NPU的对比
| 特性 | NPU | TSP |
|---|---|---|
| 推理速度 | 高(100-200令牌/秒) | 极高(500令牌/秒) |
| 功耗 | 低(50-150W) | 低(30-70W) |
| 内存带宽 | 中等(10-20TB/s) | 80TB/s |
| 确定性执行 | 无 | 有 |
未来发展趋势
异构计算融合
未来,GPU、NPU和TSP的混合部署将成为趋势。通过智能调度系统,可以根据任务特点动态分配最适合的处理器,优化资源利用和性能表现。
专用LLM加速器
随着LLM的不断发展,专用LLM加速器将逐渐成为主流。例如,Groq正在研发下一代TSP架构,进一步提升推理速度,降低延迟。
软件栈统一与开发工具优化
MLIR等开源编译器将促进标准化,提高跨平台兼容性。跨平台优化工具链将简化开发流程,降低学习成本,加速模型上线。
结论
TSP架构通过创新的设计和高性能的硬件,为大语言模型的推理任务提供了革命性的解决方案。其极高的推理速度、低功耗和高能效比,使得Groq LPU在高并发推理任务中具有显著的优势。随着技术的发展和软件生态的成熟,TSP架构将在AI芯片领域占据重要地位,推动大语言模型的进一步发展。




