近年来,大语言模型(LLM)在自然语言处理领域取得了显著进展,成为AI技术发展的核心驱动力之一。然而,如何高效地应用LLM技术,尤其是在实际产品中实现其潜力,仍然是许多开发者和企业面临的挑战。Hamel Husain发布的免费教程系列《Mastering LLMs》为这一问题提供了系统性的解决方案,涵盖了从评估到检索增强生成(RAG)再到微调的全方位知识。
什么是检索增强生成(RAG)?
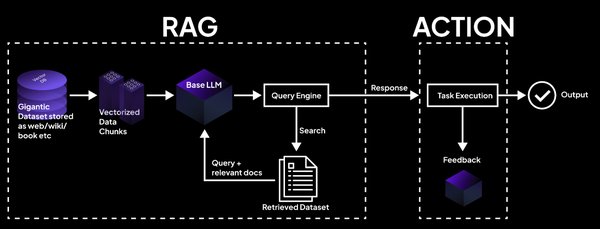
检索增强生成(Retrieval-Augmented Generation, RAG)是一种结合信息检索(IR)与文本生成的技术。其核心思想是通过检索相关文档或知识库,为LLM提供上下文信息,从而提高生成内容的准确性和相关性。RAG在处理需要广泛背景知识的任务(如问答、摘要生成等)时表现尤为出色。
RAG的核心组件
- 文档加载与拆分:从多种格式(如PDF、JSON、HTML)中加载文档,并将其拆分为语义上有意义的块。
- 嵌入模型:将文本转换为向量表示,以便进行语义搜索。
- 向量数据库:存储嵌入向量,并高效检索与查询最相似的数据。
- 协调器:将LLM与工具、数据库等连接,增强其能力。
RAG的进阶技术
除了基础RAG管道,高级技术如查询构造、代理工具和后处理进一步提升了RAG的性能。例如,通过SQL或图数据库访问结构化数据,或使用多查询检索器优化用户指令。
RAG与DeepSearch的对比
传统的RAG模式通常将检索到的文档直接输入LLM以生成答案。然而,DeepSearch模式提供了更灵活的工具化替代方案。DeepSearch允许模型运行多次搜索(如向量搜索、全文搜索等),并通过循环迭代尝试找到最佳答案。尽管DeepResearch(将多次搜索结果整合为报告)看起来更吸引人,但其对“研究”质量的误导性仍需警惕。
微调与评估:优化LLM的关键
监督式微调
监督式微调(Supervised Fine-Tuning, SFT)是在已标注数据集上对预训练模型进行再次训练的过程。完全微调(Full Fine-Tuning)虽然效果更好,但效率较低。相比之下,LoRA(低秩适配器)和QLoRA(量化低秩适配器)等参数高效技术(PEFT)显著降低了计算成本。
通过人类反馈进行强化学习(RLHF)
RLHF通过人工反馈优化LLM的输出,使其更符合人类偏好。尽管RLHF比SFT更复杂,但它被认为是提升LLM性能的重要步骤。
评估LLM
评估LLM的可靠方法包括传统指标(如困惑度和BLEU分数)、通用基准(如Open LLM排行榜)和特定任务基准(如PubMedQA)。然而,最可靠的评估仍然是用户接受率或人工比较。
总结
《Mastering LLMs》教程系列为开发者提供了从基础到高级的全面指导,帮助他们在实际产品中高效应用LLM技术。无论是通过RAG增强模型的知识检索能力,还是通过微调和RLHF优化模型性能,这些技术都为AI产品的成功落地提供了有力支持。对于希望深入探索LLM领域的开发者来说,这些资源无疑是不可或缺的宝贵指南。





