Transformer架构的核心组成
Transformer架构作为大语言模型(LLM)的核心,彻底改变了自然语言处理(NLP)领域。其核心组成部分包括:
-
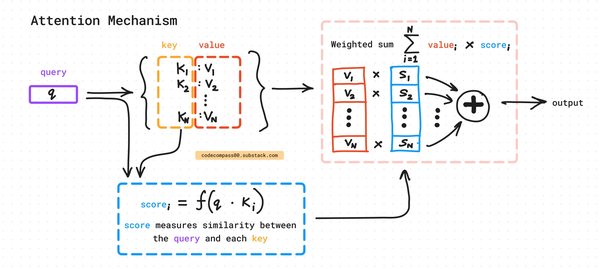
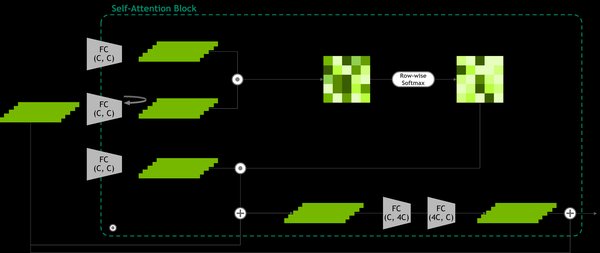
注意力机制:Transformer通过自注意力机制捕捉输入序列中不同部分之间的关系,从而更好地理解上下文。
-
前馈层:在注意力机制之后,前馈层对数据进行进一步处理,增强模型的表达能力。
-
缓存计算:通过缓存计算,Transformer能够高效处理长序列数据,减少计算复杂度。
语言数值表示的演变
Transformer模型的成功离不开语言数值表示的演变。从传统的词袋模型到词嵌入(如Word2Vec),再到Transformer的上下文感知表示,语言数值表示技术不断进化,为模型提供了更丰富的语义信息。

实际应用与挑战
Transformer模型在实际应用中展现了强大的能力,例如:
-
生成式AI:以ChatGPT为代表的生成式AI模型,能够生成高质量的文本、代码等内容。
-
教育领域:生成式AI为教育带来了新的可能性,但也引发了关于公平性、偏见和伦理问题的讨论。
-
研究与开发:Hugging Face Transformers库为研究人员和开发者提供了便捷的工具,推动了模型的快速迭代与应用。
未来展望
随着Transformer技术的不断发展,其在NLP及其他领域的应用将更加广泛。然而,如何解决模型中的偏见、确保数据安全与隐私,以及制定合理的伦理规范,仍是未来需要重点关注的课题。
通过理解Transformer大语言模型的工作原理,我们不仅能够更好地利用这一技术,还能为未来的创新与应用奠定坚实的基础。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...








AI-magic收录了大量国内外AI工具箱,包括AI写作、图像、视频、音频、编程等各类AI工具,以及常用的AI学习、技术、和模型等信息,让你轻松加入人工智能浪潮。