ZeRO优化策略:超大规模模型训练的关键技术
引言
在超大规模模型训练中,如何高效利用计算资源是一个核心问题。《Ultra-Scale Playbook》详细探讨了现代LLM训练的关键技术,其中ZeRO优化策略尤为突出。本文将深入解析ZeRO优化策略的原理、应用及实际案例,揭示其在超大规模模型训练中的重要性。
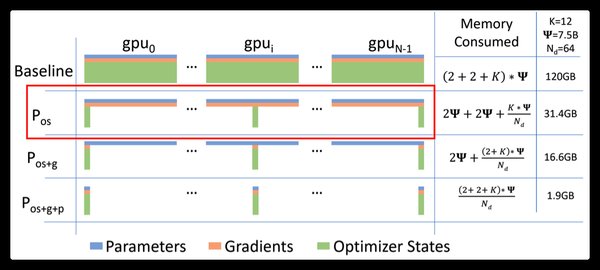
ZeRO优化策略的原理
ZeRO(Zero Redundancy Optimizer)是一种通过减少冗余数据来优化大规模模型训练的技术。它通过将模型参数、梯度和优化器状态分布在多个GPU上,从而显著降低内存占用和通信开销。
ZeRO的三个阶段
- ZeRO-1:优化器状态分区,减少内存占用。
- ZeRO-2:梯度分区,进一步降低内存需求。
- ZeRO-3:模型参数分区,实现最大程度的内存节省。
ZeRO优化策略的应用
ZeRO优化策略在超大规模模型训练中具有广泛的应用,特别是在DeepSeek等项目中表现尤为突出。
DeepSeek的成功实践
DeepSeek通过采用ZeRO优化策略,成功在500万美元的预算内完成了大规模模型训练。具体措施包括:
– FP8混合精度训练:加速训练并降低GPU内存使用。
– DualPipe算法:提高流水线并行效率,减少通信开销。
– 跨节点All-to-All通信优化:充分利用IB和NVLink带宽,节约流式多处理器资源。
ZeRO优化策略的实际案例
DeepSeek的HAI-LLM框架
DeepSeek自研的HAI-LLM框架集成了ZeRO优化策略,支持多种并行模式,如张量并行(TP)、流水线并行(PP)、全共享数据并行(FSDP)等。通过优化数据排队和GPU通信,HAI-LLM框架显著提升了训练效率。
显存节省技术
DeepSeek采用了一系列显存节省技术,包括:
– RMSNorm和MLA Up-Projection的重新计算:在反向传播期间重新计算激活值,减少显存占用。
– CPU内存中保存EMA:将指数平均数指标保存在CPU内存中,释放GPU显存。
– 多标记预测(MTP)中共享嵌入和输出头:通过DualPipe策略共享参数和梯度,提升显存效率。
ZeRO优化策略的未来发展
随着大模型架构的不断发展,ZeRO优化策略也在持续进化。未来,ZeRO优化策略可能会在以下几个方面取得突破:
– 更高效的通信机制:进一步优化跨节点通信,减少延迟和带宽占用。
– 更智能的负载均衡:通过动态调整负载,确保每个GPU的利用率最大化。
– 更广泛的应用场景:将ZeRO优化策略应用于更多领域,如多模态模型训练和边缘计算。
结论
ZeRO优化策略是超大规模模型训练的关键技术,通过减少冗余数据和优化通信机制,显著提升了训练效率和资源利用率。DeepSeek的成功实践证明了ZeRO优化策略在实际应用中的巨大潜力。未来,随着技术的不断进步,ZeRO优化策略将继续推动大模型训练的发展,为AI领域的突破提供强大支持。
通过《Ultra-Scale Playbook》的深入解析,我们可以看到,掌握ZeRO优化策略不仅是技术人员的必备技能,更是推动AI大众化的关键一步。希望本文能为读者提供有价值的参考,助力大家在超大规模模型训练中取得更大的成功。






