
强化学习与大型语言模型的结合
近年来,强化学习(RL)在大型语言模型(LLM)中的应用成为研究热点。DeepSeek R1模型的研究表明,将RL与可验证的输出(如数学问题或事实问答)结合,可以显著提升模型性能。然而,这种结合也带来了新的挑战,例如模型生成的可读性和可用性问题。
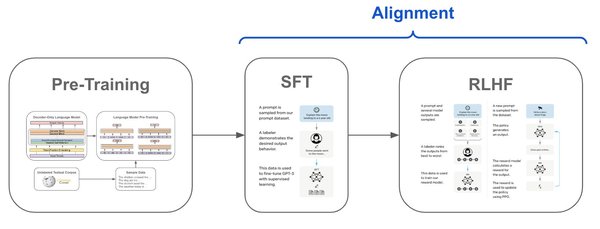
监督微调与强化学习的协同作用
为了解决这些问题,研究者采用了监督微调(SFT)和RL的组合策略。SFT通过精心标注的数据集引导模型学习特定任务,而RL则通过奖励机制优化模型的输出质量。这种协同作用不仅提高了模型的准确性,还增强了其在实际应用中的可靠性。
模型蒸馏的优势
研究发现,从大型RL训练模型中蒸馏出较小模型,比直接将RL应用于小模型更有效。蒸馏过程保留了大型模型的性能优势,同时降低了计算资源的需求。这种方法在DeepSeek R1的研究中得到了验证,并成为提升模型效率的重要策略。
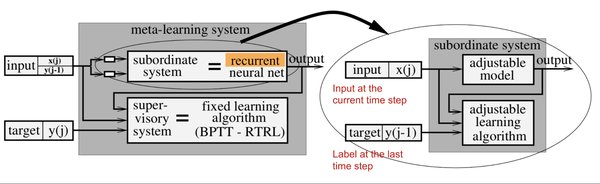
元强化学习优化测试时计算
为了进一步提升模型的推理效率,研究者提出了元强化学习(MRT)的概念。MRT通过优化测试时计算资源的使用,使模型能够在有限的token预算内生成高质量的响应。以下是MRT的关键特点:
- 探索与利用的平衡:MRT鼓励模型在生成响应时进行适度的探索,以发现更优的解决方案,同时避免过度消耗计算资源。
- 密集奖励机制:通过引入基于进展的奖励,MRT能够更精准地评估每个推理步骤的贡献,从而优化模型的输出质量。
MRT的实验结果
在多项基准测试中,MRT的表现显著优于传统的RL方法。例如,在AIME 2024和AIME 2025数据集上,MRT的准确率比标准RL方法高出2-3倍,同时token效率提高了1.5倍。这表明MRT在提升模型性能的同时,也显著降低了计算成本。
未来研究方向
尽管RL在LLM中的应用取得了显著进展,但仍有许多问题需要解决。例如,如何进一步提高模型在开放性任务(如创意写作)中的表现,以及如何设计更高效的奖励机制以应对复杂的推理任务。这些问题的解决将为RL在LLM中的应用开辟新的可能性。
总结
强化学习在大型语言模型中的应用展现了巨大的潜力,特别是在结合监督微调和模型蒸馏的策略下。通过引入元强化学习,研究者进一步优化了模型的推理效率,为未来的研究提供了新的方向。随着技术的不断发展,RL有望在更多领域发挥重要作用,推动人工智能的进一步进步。




