引言
随着生成式人工智能的快速发展,大语言模型(LLM)已成为AI领域的核心技术之一。然而,训练和微调大语言模型往往需要巨大的计算资源和时间成本。近年来,Llama模型与LoRA(Low-Rank Adaptation)微调技术的结合,为高效训练大语言模型提供了新的解决方案。本文将深入探讨这一技术组合的优势与应用场景。
Llama模型与LoRA微调技术概述
Llama模型
Llama是由Meta开源的大语言模型系列,以其高效性和灵活性著称。与GPT系列相比,Llama在参数规模与计算效率之间取得了良好平衡,特别适合在资源有限的环境下进行训练和部署。
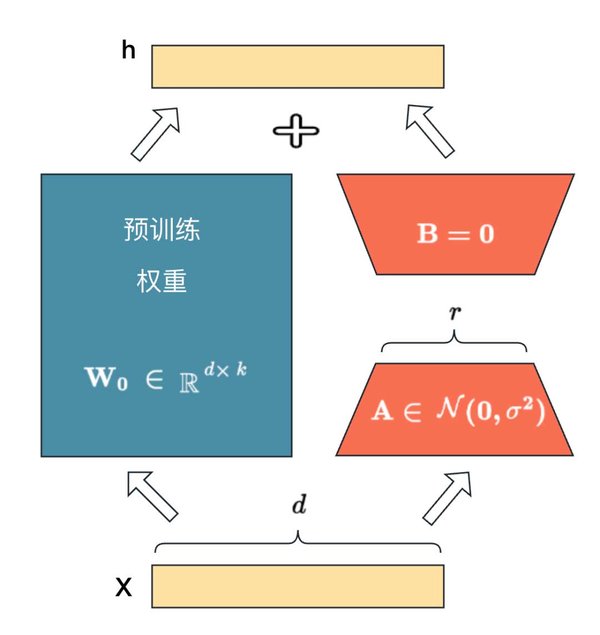
LoRA微调技术
LoRA是一种低秩适应技术,通过引入低秩矩阵来微调预训练模型,从而大幅减少训练参数和计算成本。LoRA的核心思想是仅对模型的部分参数进行微调,而不是对整个模型进行全量更新,这使得微调过程更加高效。
Llama+LoRA微调的优势
-
高效性
LoRA通过减少微调参数,显著降低了计算资源需求。例如,使用LoRA微调Llama模型时,训练成本仅为传统方法的十分之一。 -
灵活性
LoRA允许开发者针对特定任务进行快速微调,而无需重新训练整个模型。这种灵活性使得Llama+LoRA组合在行业模型训练中具有广泛应用前景。 -
性能优化
尽管LoRA减少了参数更新量,但其在任务性能上并未显著下降。实验表明,LoRA微调后的Llama模型在多项NLP任务中表现优异。
实际应用案例
行业模型训练
以医疗领域为例,开发者可以利用Llama+LoRA技术快速微调模型,使其适应医学文本分析与诊断任务。这种微调方式不仅节省了资源,还提高了模型的行业适用性。
开源生态
Llama的开源属性与LoRA的高效性相结合,为AI开发者提供了强大的工具链。例如,DeepSeek等中国企业在开源大模型领域取得的突破,正是基于类似的技术组合。
未来展望
随着AI技术的不断进步,Llama+LoRA微调技术有望在以下方面取得更大突破:
– 多模态应用:将LoRA技术扩展到图像、视频等多模态领域。
– 算力优化:结合量子计算等新兴技术,进一步提升训练效率。
– 生态建设:推动开源社区的发展,促进AI技术的普及与应用。
结语
Llama+LoRA微调技术为大语言模型的高效训练提供了新的范式。通过减少计算成本、提高灵活性,这一技术组合在行业模型训练与AI工程化落地中展现出巨大潜力。未来,随着技术的不断演进,Llama+LoRA有望在更多领域发挥重要作用,推动人工智能技术的普及与创新。

