
引言
在人工智能领域,大模型的竞争日益激烈。DeepSeek R1作为一款开源大模型,凭借其独特的技术创新和开源策略,迅速成为业界关注的焦点。本文将深入探讨DeepSeek R1的技术创新及其对AI产业的深远影响。
DeepSeek R1的技术创新
MoE架构:高效训练的核心
DeepSeek R1采用了MoE(Mixture of Experts)架构,将巨大的AI模型切割成多个子模型,每个子模型专注于特定领域。这种架构在训练和推理过程中显著提高了效率。与传统Dense架构相比,MoE架构在同等算力下具有更高的推理性能。
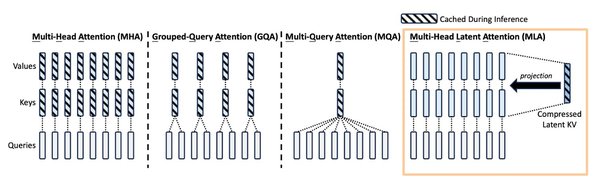
MLA多头潜在注意力机制:提升推理效率
DeepSeek R1引入了MLA(Multi-head Latent Attention)多头潜在注意力机制,通过将注意力头的键和值压缩到共享的低维潜在向量空间,大幅提高了推理效率。这种机制类似于图书馆的智能检索系统,能够快速定位所需信息,减少无效检索时间。
MTP多令牌预测:增强预测能力
DeepSeek R1还引入了MTP(Multi-token Prediction)多令牌预测机制,将预测过程分为多个并行步骤,显著提高了模型的训练效率和推理速度。这种机制生成的文字内容更加流畅和自然,更接近人类的写作方式。

DeepSeek R1的开源策略
开源技术的广泛应用
DeepSeek R1的开源策略不仅推动了AI行业的进步,也为其他AI企业提供了宝贵的经验。例如,亚马逊云科技在Amazon Bedrock上线了完全托管的DeepSeek-R1模型,数千客户已通过该平台部署了DeepSeek-R1模型。
开源对AI产业的深远影响
DeepSeek的开源做法使得更多的AI企业开始考虑加入开源阵营,从根本上促进了整个AI行业的交流与学习。开源策略不仅降低了AI模型的推理成本,还推动了实时交互等方面的显著体验提升。
DeepSeek R1与通用人工智能(AGI)
AGI的现状与挑战
当前,业界对于AGI的具体内涵和实现路径仍然模糊。DeepSeek R1通过强化学习等技术,展示了AI模型在自主学习方面的潜力。然而,AGI的实现仍面临诸多挑战,如模型泛化、实时处理等问题。
DeepSeek R1的AGI探索
DeepSeek R1通过NSA(Native Sparse Attention)注意力机制,显著提升了长文本训练和推理的效率。这种机制为处理超长文本、复杂推理任务提供了新的技术方向,使AI模型能够记住更多的细节,更接近AGI的实现。
结论
DeepSeek R1凭借其技术创新和开源策略,不仅在AI大模型领域取得了显著成就,也为通用人工智能(AGI)的发展提供了新的技术方向。随着AI产业的不断进步,DeepSeek R1将继续引领AI技术的创新与发展。
通过本文的探讨,我们可以看到DeepSeek R1在AI大模型领域的独特地位和深远影响。未来,随着更多企业和研究机构的加入,AI技术将迎来更加广阔的发展前景。







