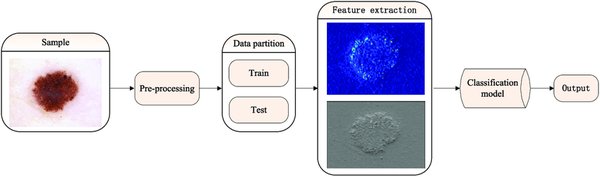
LLaVA-NeXT的特征提取与疾病识别能力
LLaVA-NeXT作为一种多模态大模型,在特征提取方面表现出色,尤其在医学图像和文本报告的处理上。研究表明,LLaVA-NeXT的特征提取能力与MAVL相当,但在疾病识别任务中,MAVL显著优于LLaVA-NeXT。这一性能差距主要源于LLaVA-NeXT未能充分利用提取的特征进行有效的疾病识别。
解码端特征对齐训练(DFAT)
为了提升LLaVA-NeXT在疾病识别任务中的表现,研究者提出了解码端特征对齐训练(DFAT)策略。该策略通过引入特殊标记,利用解码器的自回归生成能力,提取图像和文本的全局表示。此外,DFAT还结合了跨模态对比损失,优化模型学习判别特征的能力。
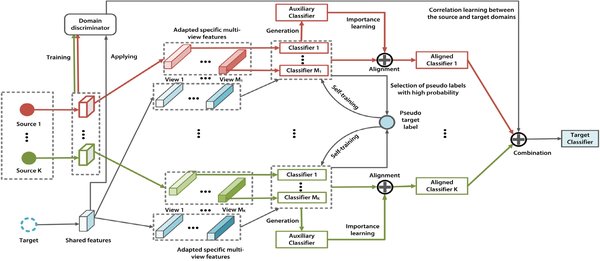
领域知识锚定模块(DKAM)
在医学图像和文本报告的细粒度对齐过程中,LLaVA-NeXT面临语义类别差距的挑战。为此,研究者设计了领域知识锚定模块(DKAM),利用模型内在的医学知识提取疾病类别的语义信息,构建疾病描述向量,作为医学图像和文本报告之间的中介桥梁,建立稳定的三模态关系。
类别知识引导损失
为了进一步增强医学图像、文本报告和疾病类别之间的关联,LLaVA-NeXT引入了类别知识引导损失。该损失函数通过加强相似图像与对应文本报告之间的关联,提升模型在疾病识别任务中的表现。
与MM1的比较
与苹果自研的大模型MM1相比,LLaVA-NeXT在多图像推理和少样本提示方面存在一定限制。尽管MM1在多模态任务中表现出色,但其参数规模较小,可能限制其在复杂任务中的表现。LLaVA-NeXT通过引入DFAT和DKAM等创新策略,在医学领域的多模态任务中展现出独特优势。
未来展望
LLaVA-NeXT在多模态大模型领域的创新为医学图像和文本报告的处理提供了新的思路。未来,研究者将继续优化模型的特征提取和疾病识别能力,探索更多跨模态对齐策略,以提升模型在复杂任务中的表现。
通过以上分析,我们可以看到LLaVA-NeXT在多模态大模型领域的创新与挑战。尽管其在某些方面仍有提升空间,但其在医学领域的应用前景令人期待。





