数据集规模突破:从10亿到1000亿
谷歌DeepMind团队近日发布了史上最大规模的视觉语言数据集WebLI-100B,包含1,000亿对图像-文本数据。这一数据集在WebLI的基础上构建,规模扩大了10倍,并保持了高质量抓取策略。WebLI-100B的发布标志着视觉语言模型(VLMs)领域迈入了一个全新的阶段。
过去,模型的发展遵循“大力出奇迹”的原则:数据规模越大,模型性能越高。WebLI-100B的诞生验证了这一原则的延续性,尤其是在多模态AI领域。

数据规模与文化多样性的关系
尽管WebLI-100B在传统基准测试(如ImageNet和COCO)上的提升有限,但其在文化多样性和低资源语言任务中的表现却令人瞩目。例如,泰卢固语(Telugu)在数据集中仅占0.036%,但其表现显著提升。这一发现揭示了数据规模对构建真正包容的多模态系统的重要性。
数据规模对文化多样性的影响
| 数据集规模 | 文化多样性任务提升 | 低资源语言任务提升 |
|---|---|---|
| 100亿 | 1% | 0.5% |
| 1000亿 | 5.8% | 1% |
数据表明,当数据集规模从100亿扩展到1000亿时,文化多样性任务的性能提升显著高于传统任务。
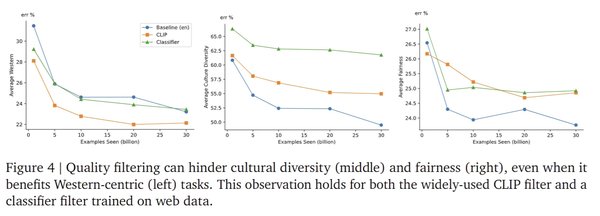
数据过滤与多样性的权衡
在构建WebLI-100B的过程中,研究团队发现,传统的质量过滤器(如基于CLIP的过滤器)虽然提高了数据质量,但可能无意中限制数据集的多样性。例如,CLIP过滤器在以西方为中心的任务中表现出色,但在涉及文化多样性的任务中表现较差。
数据过滤对不同任务的影响
| 任务类型 | 数据过滤效果 |
|---|---|
| 西方中心任务 | 提升显著 |
| 文化多样性任务 | 表现下降 |
| 低资源语言任务 | 表现下降 |
这一发现提醒我们,在追求数据质量的同时,需谨慎平衡多样性与公平性。
实验设置与评估
为了评估WebLI-100B的潜力,研究团队构建了三个子集:WebLI-1B、WebLI-10B和WebLI-100B,并训练了SigLIP模型。实验结果显示,数据规模的扩展对低资源语言和文化多样性任务的提升尤为显著。
模型性能评估
| 数据集规模 | ImageNet性能提升 | 文化多样性任务提升 |
|---|---|---|
| 10亿 | 0.5% | 1% |
| 100亿 | 0.8% | 1.5% |
| 1000亿 | 1% | 5.8% |
数据表明,数据规模的扩展对传统任务的提升逐渐递减,但对文化多样性任务的提升显著。
未来展望
WebLI-100B的发布为AI多模态发展开辟了新方向。它不仅验证了数据规模对模型性能的重要性,还揭示了数据多样性和公平性在AI发展中的关键作用。未来,如何在数据规模与多样性之间找到最佳平衡,将成为AI研究的重要课题。
WebLI-100B的诞生标志着AI多模态领域迈入了一个全新的阶段,为构建真正包容的智能系统提供了重要基础。






