
分形生成模型:AI与自然界的完美融合
在2025年,何恺明团队提出的分形生成模型(Fractal Generative Models)引发了AI领域的广泛关注。这一模型借鉴了自然界中的分形结构,通过递归调用原子生成模块,构建了自相似的生成架构。分形生成模型不仅在计算效率上实现了飞跃,还首次将逐像素建模的精细分辨率提升了4000倍。
分形生成模型的核心架构
- 递归结构:每个生成模块内部嵌套更小的生成模块,形成自相似的分形架构。
- 计算效率:通过分而治之的策略,模型能够高效处理高维数据的联合分布。
- 应用场景:在像素级图像生成中,分形生成模型展现了强大的生成能力,尤其在256×256分辨率的图像生成任务中表现出色。
分形生成模型不仅是一种新的生成建模范式,更是AI设计与自然界奥秘的完美结合。正如研究团队所言:“通往真正智能的道路,或许就是更深入理解、模拟自然界已有的设计模式。”
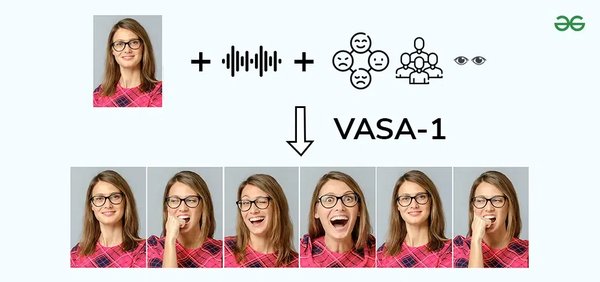
数字人技术:VASA-1的突破
在视觉生成模型的另一前沿,微软亚洲研究院推出的VASA-1技术为虚拟数字人领域带来了革命性突破。VASA-1能够通过单张静态图像和一段语音音频,生成逼真的对话面部动画,实现精准的唇语同步和自然的表情动作。
VASA-1的技术亮点
- 单图生成:无需针对特定人物训练,仅需一张人脸图片和一段音频即可生成视频。
- 真实感:通过精确的音频与唇部动作同步,显著增强了生成视频的生动性。
- 应用潜力:该技术不仅提升了虚拟数字人的逼真度,还为即时互动需求提供了新的解决方案。
VASA-1的推出,标志着AI在虚拟数字人领域的技术成熟,也为未来的交互式应用打开了新的可能性。
视觉生成模型的未来展望
视觉生成模型的快速发展,不仅推动了AI技术的进步,也为相关产业带来了新的机遇。从分形生成模型到数字人技术,这些创新成果展示了AI在图像生成、虚拟交互等领域的巨大潜力。
未来发展方向
- 多模态融合:将视觉生成模型与语音、文本等多模态技术结合,打造更智能的交互系统。
- 实时生成:进一步提升模型的实时生成能力,满足更多应用场景的需求。
- 跨领域应用:探索视觉生成模型在医疗、教育、娱乐等领域的应用,推动AI技术的普及。
随着技术的不断演进,视觉生成模型将继续引领AI产业的创新浪潮,为人类带来更智能、更便捷的未来生活。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...





AI-magic收录了大量国内外AI工具箱,包括AI写作、图像、视频、音频、编程等各类AI工具,以及常用的AI学习、技术、和模型等信息,让你轻松加入人工智能浪潮。