引言
近年来,人工智能在文本和视觉领域的融合取得了显著进展,而多模态AI模型的出现更是为这一领域带来了新的可能性。杭州的一个95后研究团队通过将DeepSeek-R1的训练方法从纯文本领域迁移到视觉语言领域,开发了名为VLM-R1的开源项目。该项目不仅在全球最大的代码托管平台GitHub上迅速走红,还因其卓越的推理能力和多模态转换能力备受关注。本文将深入探讨VLM-R1的核心技术——Group Relative Policy Optimization (GRPO),并分析其如何革新多模态AI的训练方法。
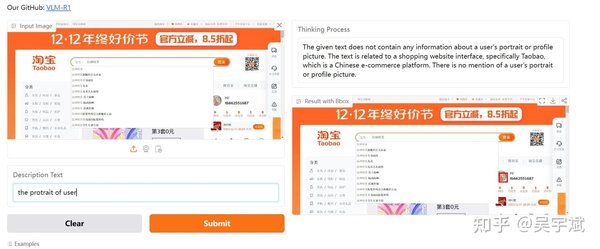
GRPO:从文本到视觉的迁移
VLM-R1的核心技术灵感来源于DeepSeek R1模型,后者通过GRPO算法在文本领域实现了高效的推理能力。GRPO是一种创新的强化学算法,其核心思想是通过生成多个解答并在组内进行比较,从而优化模型的输出。这一方法在文本领域已取得了显著成果,而VLM-R1则将其成功迁移到视觉语言领域,实现了多模态AI的训练优化[citation:1]。
GRPO的核心机制
GRPO的独特之处在于其三步优化流程:
1. 生成多个解答:模型针对同一问题生成多种可能的解答,类似于学生在解题时尝试不同方法。
2. 组内评估:通过相对评估而非绝对评分,选出组内最优解答。
3. 优化调整:根据评估结果,强化优质解答并减少错误输出。
这一机制不仅提高了模型的推理能力,还使其在处理复杂视觉信息时表现出色[citation:1]。
VLM-R1的技术突破
VLM-R1的成功离不开其在多模态转换和推理能力上的创新。以下是该项目的几大技术亮点:
多模态转换能力
VLM-R1能够将文本与视觉信息无缝结合,例如将图像描述转换为文本,或根据文本生成对应的视觉内容。这种能力得益于GRPO算法的多任务适应性,使模型能够在不同模态之间灵活切换[citation:1]。
复杂视觉信息的推理
与传统的视觉模型不同,VLM-R1不仅能够识别图像中的物体,还能理解其背后的逻辑关系。例如,在面对复杂的视觉场景时,模型可以通过推理生成详细的描述或回答相关问题[citation:1]。
开源与社区贡献
VLM-R1在GitHub上线仅一周就获得了2000多个星标收藏,迅速登上热门趋势榜。其开源性质吸引了全球开发者的关注,推动了多模态AI技术的进一步发展[citation:1]。
GRPO在多模态AI中的优势与挑战
尽管GRPO在VLM-R1中取得了显著成果,但其在多模态AI中的应用仍面临一些挑战:
优势
- 高效学习:GRPO通过组内比较优化模型输出,减少了传统强化学中报酬模型的需求。
- 多任务适应性:GRPO的灵活性使其能够适应文本、视觉等多种任务[citation:1]。
挑战
- 计算成本:生成多个解答会增加计算资源消耗,尤其是在处理大规模视觉数据时。
- 报酬函数设计:在多模态任务中,如何设计合适的报酬函数仍是一个难题[citation:1]。
未来展望
随着技术的不断进步,GRPO在多模态AI中的应用前景广阔。未来的研究方向可能包括:
– 计算效率优化:通过并行处理或GPU资源的高效利用,降低计算成本。
– 动态报酬设计:开发自适应报酬函数,以更好地适应多模态任务的需求[citation:1]。
结语
VLM-R1的成功展示了GRPO算法在多模态AI中的巨大潜力。通过将DeepSeek R1的训练方法迁移到视觉语言领域,杭州的研究团队为多模态AI的发展开辟了新的道路。未来,随着技术的进一步优化,GRPO有望在更多领域实现突破,推动人工智能的持续进化。






