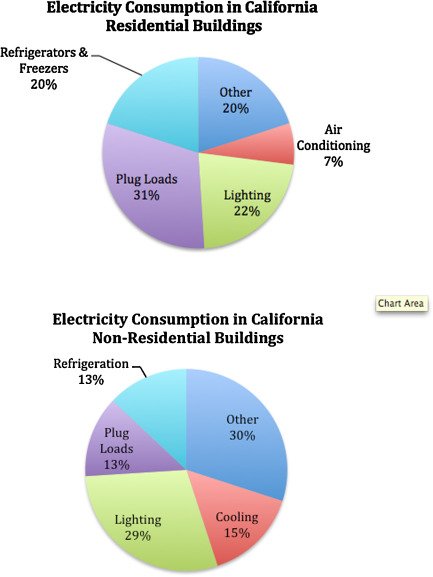

引言:大语言模型的效率挑战
随着大语言模型(LLMs)的快速发展,模型的能力随着参数数量的增加而显著提升。然而,这种增长也带来了巨大的计算负担,尤其是在长上下文处理和推理效率方面。传统的多头注意力机制(MHA)虽然在处理输入序列时表现出色,但随着序列长度的增加,键值(KV)缓存的规模也随之扩大,导致推理时的计算量和内存占用急剧上升。这一挑战促使研究人员寻找更高效的解决方案。
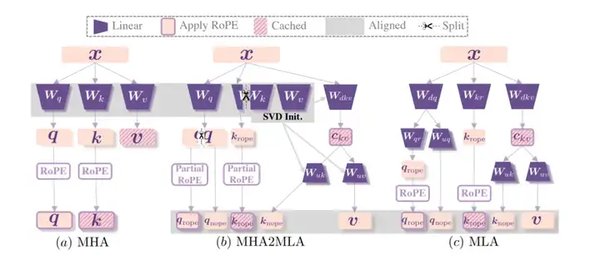

DeepSeek-R1的创新:从MHA到MLA
DeepSeek团队提出的DeepSeek-R1模型,通过引入多头潜在注意力(MLA)机制,显著降低了KV缓存的内存占用。MLA利用低秩联合压缩技术,将传统的KV缓存转化为低秩潜在向量,从而在保持模型性能的同时,大幅减少了推理时的计算负担。这一创新为大语言模型的高效应用提供了新的可能性。
![]()
MHA2MLA微调方法的核心技术
MHA2MLA微调方法的成功依赖于两项关键技术:partial-RoPE和低秩近似。partial-RoPE通过对注意力得分的维度敏感度进行计算,识别并去除对结果贡献较小的冗余维度,从而在保证性能的情况下降低了计算量。低秩近似则通过对预训练的键和值参数进行矩阵分解,利用低秩矩阵替代原始矩阵,进一步减少了推理时的计算量和内存占用。
实验效果与未来展望
实验结果显示,采用MHA2MLA方法的Llama2-7B模型,在减少KV缓存大小达92.19%的同时,性能仅下降了0.5%。这一结果证明了MHA2MLA在性能与计算成本之间的良好平衡。此外,MHA2MLA还表现出与量化技术的良好兼容性,通过将模型与4-bit量化技术结合,能实现高达96.87%的压缩率,而精度损失控制在可接受范围内。
展望未来,DeepSeek团队计划在更多开源大语言模型中验证MHA2MLA的有效性,推测该技术将在产业应用中得到广泛认可。这一技术革新不仅为技术开发人员提供了全新的思路,也为行业的发展带来了元动力。
结语
DeepSeek-R1通过引入MLA机制和MHA2MLA微调方法,为大语言模型的高效应用提供了新的解决方案。这一创新在降低计算成本和内存占用方面的显著效果,为大语言模型的未来发展指明了方向。随着智能化时代的到来,这些前沿技术的深入理解与应用,将进一步提升AI工具的创作效率,推动行业的持续发展。



