
结构化自注意力掩码机制的背景与意义
在时间序列预测领域,传统的Transformer模型在处理多预测范围任务时,往往需要针对每个预测范围进行单独训练,这不仅增加了计算成本,还可能导致预测结果的不一致性。ElasTST模型通过引入结构化自注意力掩码机制,成功解决了这一问题。该机制的核心思想是通过一次训练,实现跨多预测范围的一致性和准确性。
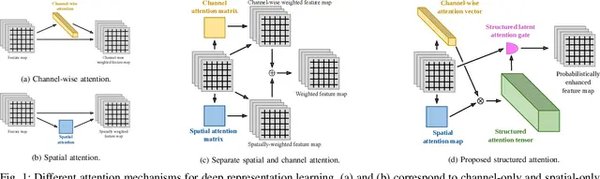
结构化自注意力掩码机制的工作原理
结构化自注意力掩码机制在ElasTST模型中起到了关键作用。其工作原理主要包括以下几个步骤:
-
自注意力计算:首先,模型通过自注意力机制计算输入序列的注意力权重。具体来说,模型会生成查询矩阵Q、键矩阵K和值矩阵V,然后计算Q与K的点积,得到注意力分数矩阵QKT。
-
标准化与Softmax操作:对QKT矩阵进行标准化和Softmax操作,得到归一化的注意力权重矩阵A。该矩阵的大小为n x n,其中n为输入序列的长度。
-
结构化掩码应用:在得到注意力权重矩阵A后,模型会应用结构化掩码,确保解码器仅使用先前的位置生成每个位置的输出。这种掩码机制不仅提高了模型的预测准确性,还增强了其鲁棒性。
-
结果矩阵生成:最后,模型将注意力权重矩阵A与值矩阵V相乘,得到最终的自注意力结果矩阵Z。该矩阵包含了输入序列的上下文信息,为后续的预测任务提供了坚实的基础。
结构化自注意力掩码机制的优势
结构化自注意力掩码机制在ElasTST模型中的应用,带来了以下几个显著优势:
-
一致性:通过一次训练实现跨多预测范围的一致性,减少了模型训练的时间和计算成本。
-
准确性:结构化掩码机制确保了模型在预测过程中仅使用有效的信息,提高了预测的准确性。
-
鲁棒性:该机制增强了模型在面对不同数据集和预测任务时的鲁棒性,使其在各种复杂场景下都能表现出色。
实验验证与结果
ElasTST模型在各种数据集的长短期预测任务中进行了广泛的实验验证。实验结果表明,结构化自注意力掩码机制在提高模型预测准确性和鲁棒性方面表现卓越。具体来说,ElasTST在多个预测范围上的表现均优于传统Transformer模型,尤其是在处理长序列预测任务时,其优势更加明显。
结论
结构化自注意力掩码机制作为ElasTST模型的核心创新,通过一次训练实现跨多预测范围的一致性和准确性,显著提升了时间序列预测模型的性能。其卓越的实验表现,不仅验证了该机制的有效性,也为未来时间序列预测领域的研究提供了新的思路和方向。







