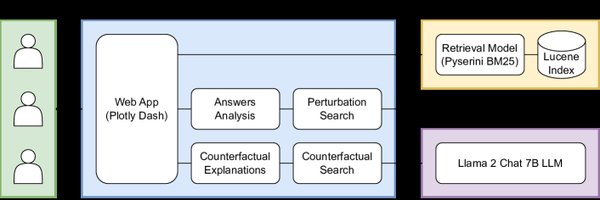

LLM的自我解释能力:反事实解释的挑战
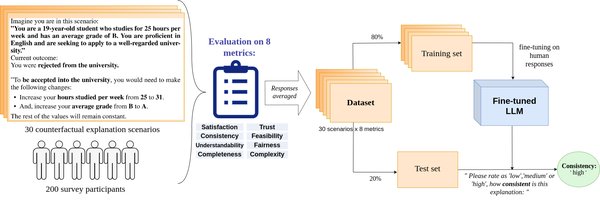
大语言模型(LLM)在生成自然语言和解决复杂任务方面展现了强大的能力,但其自我解释能力仍存在显著局限性。最近的研究表明,LLM在生成反事实解释(Self-Generated Counterfactual Explanations, SCEs)时表现不佳。反事实解释旨在通过假设性场景解释模型的预测,但实验显示,LLM生成的SCEs往往无法保持与原始预测的一致性。
研究发现,LLM在生成SCEs时过度依赖上下文信息,导致其解释能力受到限制。例如,模型的预测结果会受到原始预测和生成指令的显著影响。这一现象表明,LLM在解释自身行为时仍缺乏足够的独立性和逻辑一致性。这些发现与近期其他关于LLM自我解释能力的研究相呼应,进一步揭示了LLM在透明性和可解释性方面的不足。
Data Attribution:理解模型行为的关键
在ICML 2024上,Andrew Ilyas等人深入探讨了Data Attribution问题,这一问题在LLM和生成式AI(GenAI)背景下变得愈发重要。Data Attribution旨在理解训练数据对模型行为的影响,为模型健壮性和选择性遗忘(Unlearning)等应用提供了新的研究方向。
Data Attribution的核心挑战
-
训练数据的影响:如何量化特定数据点对模型预测的贡献。
-
模型健壮性:通过Data Attribution识别关键数据,提高模型对噪声和对抗性攻击的鲁棒性。
-
选择性遗忘:利用Data Attribution技术高效删除特定数据的影响,满足隐私和合规需求。
前沿应用场景
-
模型编辑:通过Data Attribution技术对模型进行精细调整,优化其性能。
-
透明性提升:设计基于Data Attribution的解释方法,增强模型的可解释性。
-
多模态学习:将Data Attribution扩展到多模态模型,探索其在视觉-文本理解中的应用。

未来研究方向
尽管LLM在生成反事实解释方面存在局限,但其在Data Attribution领域的潜力值得深入挖掘。未来的研究可以聚焦于以下方向:
-
开发更高效的Data Attribution算法,提升其在大规模模型中的实用性。
-
结合多模态学习,探索Data Attribution在跨模态任务中的应用。
-
设计更透明的解释框架,弥补LLM在自我解释能力上的不足。
通过深入理解Data Attribution和LLM的自我解释能力,我们可以更好地优化模型性能,推动AI技术的透明性和可靠性发展。






