在大语言模型的研究中,注意力机制是核心组件之一,但其计算复杂度和内存占用一直是技术瓶颈。Flash Attention技术的出现,为解决这一问题提供了新的思路。本文将从技术原理、应用场景以及科研启示三个方面,深入探讨Flash Attention的重要性。
Flash Attention的技术原理
Flash Attention是一种快速且内存高效的精确注意力机制,其核心在于IO感知和并行优化。通过减少内存访问次数和优化计算流程,Flash Attention显著提升了注意力机制的计算效率。具体来说,Flash Attention-2在Flash Attention的基础上,进一步改进了并行性和工作分区,使得其在大规模计算中表现更为出色。
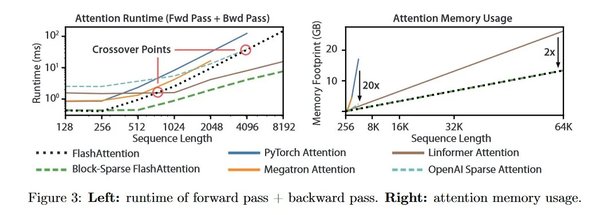

应用场景与优势
Flash Attention在大语言模型中的应用具有广泛的前景。其优势主要体现在以下几个方面:
-
计算效率提升:通过优化内存访问和并行计算,Flash Attention大幅减少了计算时间。
-
内存占用降低:IO感知机制减少了内存占用,使得模型可以在更大规模的数据上运行。
-
扩展性强:Flash Attention的设计使其易于扩展到其他深度学习任务中。
科研启示与工程能力
薛复昭博士在其研究经验中强调了工程能力的重要性。他认为,强大的工程能力不仅是实现人工智能想法的关键,还能激发创新的研究思路。Flash Attention的研发正是这一观点的体现,其背后是对底层技术和社区挑战的深入理解。
总结
Flash Attention技术在大语言模型中的应用,不仅提升了计算效率和内存利用率,还为深度学习领域的研究提供了新的方向。结合薛复昭博士的科研经验,我们可以看到,工程能力与科研创新的结合,是推动技术进步的重要动力。未来,随着Flash Attention技术的不断优化,其在深度学习领域的应用将更加广泛。
通过本文的探讨,我们希望读者能够更深入地理解Flash Attention的技术原理及其在大语言模型中的应用,同时也为科研新人提供了宝贵的经验和启示。




