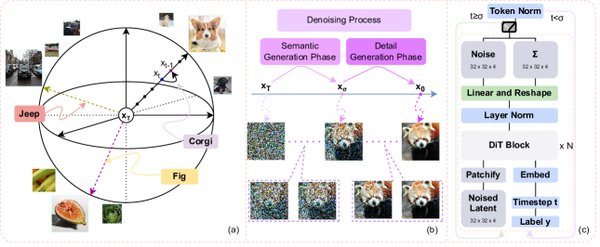
无需训练扩散模型引导方法的兴起
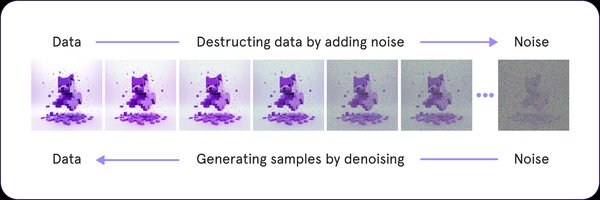
近年来,生成式AI技术在图像、视频、3D场景等多个领域取得了显著进展,其中扩散模型(Diffusion Models)因其高质量的生成效果而备受关注。然而,扩散模型的高计算成本成为其广泛应用的主要瓶颈。为了解决这一问题,研究者们提出了无需训练的扩散模型引导方法,旨在通过优化推理过程提升模型效能,而无需额外的训练成本。
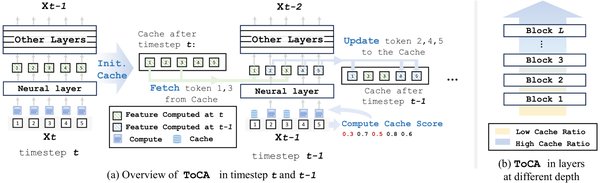
特征缓存技术的突破
特征缓存是一种无需训练的扩散模型加速方法,通过缓存前几个时间步的特征并在后续时间步中复用它们来加速推理。然而,传统的缓存方法忽略了不同token对特征缓存的敏感性差异,导致生成质量下降。上海交通大学张林峰团队提出的ToCa方法,首次引入了基于token的特征缓存策略,通过自适应选择适合缓存的token,实现了接近无损的生成加速。实验表明,ToCa在OpenSora和PixArt-α模型上分别实现了2.36倍和1.93倍的加速效果。
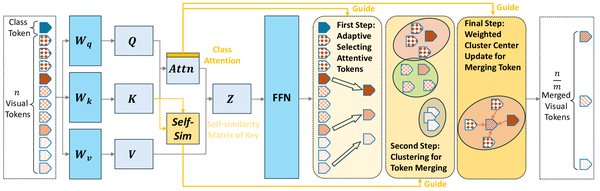
自适应策略的应用
ToCa方法的核心在于其自适应策略,具体包括以下四个方面:
-
基于Self-Attention Map的token选择:评估token对其他token的影响,保留关键token。
-
基于Cross-Attention Map的token选择:在文生图/视频任务中,增强图像token对文本token的关注分布。
-
基于缓存次数的增益策略:鼓励token在时间步上均匀计算,避免局部误差积累。
-
基于空间分布的重要性加权:确保被计算的token在空间上分布均匀,提升生成质量。
无需训练方法的优势
无需训练的扩散模型引导方法具有以下显著优势:
-
无需额外训练:直接应用于现有模型,节省训练成本和时间。
-
高效加速:通过特征缓存和自适应策略,显著提升推理速度。
-
无损生成:在加速的同时,保持生成质量不受影响。
未来挑战与研究方向
尽管无需训练方法在提升生成式AI效能方面取得了显著成果,但仍面临一些挑战:
-
复杂场景的适应性:在生成复杂3D场景时,如何进一步提升模型的适应性和生成效果。
-
误差积累的控制:在长时间步推理中,如何有效控制误差积累,避免生成质量下降。
-
多模态融合:探索无需训练方法在多模态生成任务中的应用,如图文生成、视频生成等。
结论
无需训练扩散模型引导方法为生成式AI的效能提升提供了新的路径。通过特征缓存和自适应策略,研究者们在不牺牲生成质量的前提下,显著加速了模型的推理过程。未来,随着技术的进一步发展,无需训练方法有望在更多复杂场景和多模态任务中发挥重要作用,推动生成式AI技术的广泛应用。






