
Transformer架构与视觉AI的融合
近年来,transformer架构在计算机视觉领域取得了显著进展,尤其是自监督学习模型如DINOv2的出现,为视觉AI技术带来了革命性的突破。DINOv2由Meta AI推出,专注于无标注数据的训练,支持图像分类、目标检测等任务,其性能甚至超越了传统监督模型。这一成功不仅展示了transformer架构在视觉任务中的潜力,也为大模型在AI行业中的应用开辟了新的方向。
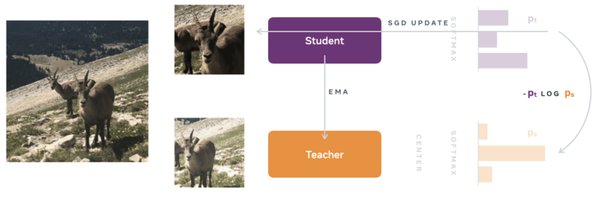
DINOv2:自监督学习的典范
DINOv2的核心优势在于其无需标注数据即可训练生成式AI的能力。这一特性使其在无监督场景中表现出色,尤其适用于数据标注成本高昂的领域,如自动驾驶和医学影像分析。然而,尽管DINOv2在图像特征提取方面表现出色,其在多模态整合方面仍有改进空间。例如,在涉及3D信息的任务中,单纯依赖2D自监督学习可能无法满足复杂场景的需求。

AI生成视频对检索系统的影响
随着AI生成内容(AIGC)的快速发展,高质量AI生成视频的创作变得愈发容易,互联网上充斥着大量此类内容。然而,这些视频对内容生态系统的影响尚未被充分研究。最新研究表明,视频检索模型在处理AI生成视频时存在明显的偏好,这种偏见不仅源于视觉信息,还与时间因素密切相关。例如,研究团队构建了一个包含13,000个AI生成视频的基准数据集,并发现现成的视频检索模型在处理这些视频时表现出明显的倾向性。
3D信息在视觉任务中的重要性
在涉及复杂场景的任务中,3D信息的重要性不容忽视。例如,在自动驾驶领域,3D理解能力对于空间定位和推理至关重要。研究表明,引入3D信息可以显著提升模型的性能。例如,Cube-LLM等模型通过整合3D理解能力,在视觉任务中表现出色。相比之下,缺乏3D信息的模型(如GPT-4V)在空间推理任务中表现较弱。
未来展望:transformer架构的持续创新
transformer架构在视觉AI领域的成功,不仅体现在DINOv2等模型的性能提升上,还在于其对多模态任务和复杂场景的适应能力。未来,随着3D信息与自监督学习的进一步整合,transformer架构有望在更多领域实现突破。例如,在视频检索系统中,通过引入3D信息并优化模型训练方法,可以有效缓解AI生成视频带来的偏见问题。
transformer架构正在推动视觉AI技术的革新,从DINOv2的自监督学习到3D理解能力的整合,这一架构展现了其在复杂任务中的巨大潜力。未来,随着技术的不断发展,transformer架构有望在更多领域实现突破,为AI行业带来更多创新成果。




