多模态学习中的Transformer架构
随着人工智能技术的不断发展,多模态学习逐渐成为研究热点。Transformer架构因其强大的自注意力机制,在多模态学习中展现出巨大潜力。特别是在结合视觉、文本和音频等多源数据时,Transformer能够有效捕捉不同模态间的关联与相互作用。
MDETR的核心思想
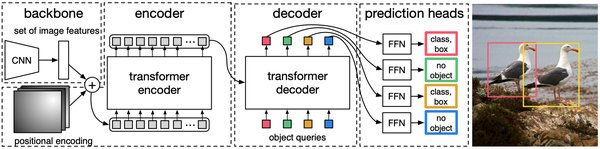
MDETR(Multimodal Detr)是GitHub上开源的一个项目,它将目标检测与文本描述相结合,进一步拓展了视觉语言任务的边界。MDETR的核心思想是通过自注意力机制,同时建模图像的视觉特征和文本的上下文信息,从而实现更精准的目标检测和文本匹配。
自注意力机制的应用
自注意力机制是Transformer架构的核心,它能够捕捉输入序列中不同位置之间的依赖关系。在多模态学习中,自注意力机制可以同时处理图像和文本数据,从而更好地理解两者之间的关联。例如,在处理文本与图像匹配任务时,MDETR能够通过自注意力机制,同时考虑图像的视觉特征和文本的上下文信息,从而实现更精准的匹配。
MDETR的技术突破
MDETR在技术上有多个突破点。首先,它将目标检测与文本描述相结合,能够同时处理视觉和文本数据。其次,MDETR通过自注意力机制,能够有效捕捉不同模态间的关联与相互作用。最后,MDETR在视觉语言任务中表现出色,进一步拓展了多模态学习的应用边界。
未来展望
随着更多模态数据的融合,Transformer架构有望推动多模态学习迈向更高的智能水平。未来,我们可以期待更多类似MDETR的项目出现,进一步推动多模态学习技术的发展。特别是在视觉语言任务、音频处理等领域,Transformer架构将发挥更大的作用。
结论
Transformer架构在多模态学习中展现出巨大潜力,特别是在结合视觉、文本和音频等多源数据时表现突出。MDETR通过将目标检测与文本描述相结合,进一步拓展了视觉语言任务的边界。未来,随着更多模态数据的融合,Transformer架构有望推动多模态学习迈向更高的智能水平。





