
SigLIP2的架构与优化
Google最新发布的视觉-语言模型SigLIP2在原始SigLIP架构的基础上进行了多项优化。SigLIP2通过结合图像和文本数据进行预训练,显著提升了跨模态任务的表现。以下是SigLIP2的主要优化点:
-
更高效的训练方法:SigLIP2采用了更高效的训练策略,减少了训练时间和资源消耗。
-
改进的损失函数:新的损失函数设计使得模型在训练过程中更加稳定,提升了模型的泛化能力。
-
扩展的数据集使用:SigLIP2使用了更大规模的数据集进行预训练,增强了模型的学习能力和表现。
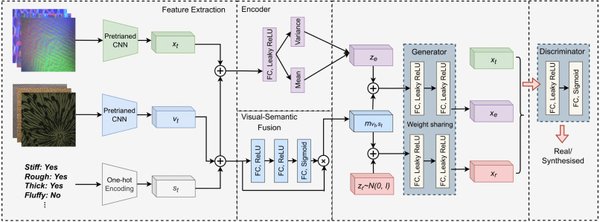
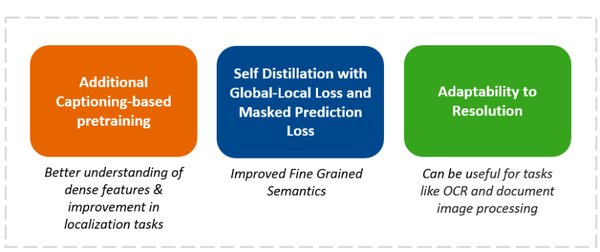
跨模态任务的卓越表现
SigLIP2在多个基准测试中取得了比前代模型更优的性能,尤其是在零样本分类和多模态理解任务上表现出色。以下是SigLIP2在具体任务中的表现:
-
零样本分类:SigLIP2在零样本分类任务中展现了强大的泛化能力,能够准确识别未见过的类别。
-
多模态理解:在多模态理解任务中,SigLIP2能够更好地结合图像和文本信息,提供更准确的理解和推理。

开源与社区支持
SigLIP2已在Hugging Face平台上开源,为开发者和研究者提供了强大的工具和资源。通过Hugging Face平台,用户可以轻松加载和使用SigLIP2模型,进行各种跨模态任务的实验和应用。
实际应用示例
以下是一个使用SigLIP2模型进行图像特征提取的示例代码:
“`python
import torch
from transformers import AutoModel, AutoProcessor
from transformers.image_utils import load_image
加载模型和处理器
ckpt = “google/siglip2-base-patch16-512”
model = AutoModel.from_pretrained(ckpt, device_map=”auto”).eval()
processor = AutoProcessor.from_pretrained(ckpt)
加载图像
image = load_image(“https://huggingface.co/datasets/merve/coco/resolve/main/val2017/000000000285.jpg”)
inputs = processor(images=[image], return_tensors=”pt”).to(model.device)
运行推理
with torch.no_grad():
image_embeddings = model.get_image_features(**inputs)
print(image_embeddings.shape)
“`
通过以上代码,用户可以轻松提取图像的特征表示,为后续的图像理解和分析任务提供支持。
总结
SigLIP2作为Google改进的视觉-语言模型,在跨模态任务中展现了卓越的性能和广泛的应用前景。通过开源和社区支持,SigLIP2为开发者和研究者提供了强大的工具,推动了视觉-语言模型领域的发展。






