引言
在人工智能领域,DeepSeek-V3的发布无疑是一场技术革命。这款拥有6710亿参数的混合专家模型(MoE),不仅刷新了AI大模型的规模记录,还通过多项创新技术显著提升了计算效率和推理能力。本文将深入探讨DeepSeek-V3的技术创新、其在AI领域的应用前景,以及创始人梁文锋的职业生涯与远见。

DeepSeek-V3的技术创新
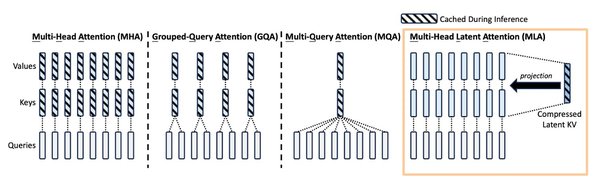
混合专家模型(MoE)与多头潜注意力(MLA)
DeepSeek-V3采用了混合专家模型(MoE)架构,每个Token处理时仅激活370亿参数,显著降低了计算资源的消耗。此外,多头潜注意力(MLA)技术的引入,通过低秩键值联合压缩技术,大幅减少了KV缓存的大小,提升了计算效率。
无辅助损失负载均衡策略
DeepSeek-V3在训练过程中采用了无辅助损失负载均衡策略,通过动态调整偏差项,确保每个专家在训练中得到合理的激活次数,从而提高了训练稳定性和模型性能。
训练框架与优化
DeepSeek-V3的训练框架采用了FP8混合精度训练、DualPipe算法和跨节点All-to-All通信优化,显著提升了训练速度和效率。这些优化措施使得DeepSeek-V3在保持大规模参数优势的同时,实现了更高的训练效率。
梁文锋的职业生涯与远见
从量化投资到AI大模型
梁文锋从浙江大学毕业后,带领团队运用机器学习技术探索全自动化交易,并于2015年成立幻方量化,一家依靠数学与人工智能进行量化投资的对冲基金公司。2023年,他成立DeepSeek,专注于人工智能大模型技术研发,并在2024年发布了DeepSeek-V2和V3模型。
开源与创新
梁文锋始终坚持“研究先行”的理念,推动DeepSeek-V3的开源,让更多开发者和研究者能够利用这一强大的AI工具。他的技术远见和领导力,使得DeepSeek在AI领域取得了显著的成就。
DeepSeek-V3的应用前景
代码生成与分析
DeepSeek-V3在代码生成和分析任务中表现出色,其MLA和DeepSeekMoE架构的改进,使得模型在处理复杂编程任务时更加高效。
推理能力与通用性
DeepSeek-V3不仅在专业领域表现出色,还具备强大的通用推理能力。其无辅助损失负载均衡策略和细粒度专家+通才专家的思路,使得模型在多个领域都能发挥出色的性能。
结语
DeepSeek-V3的发布,标志着人工智能大模型技术的一次重大突破。通过混合专家模型、多头潜注意力和无辅助损失负载均衡策略,DeepSeek-V3在计算效率和推理能力上取得了显著提升。创始人梁文锋的职业生涯与远见,为DeepSeek的发展奠定了坚实的基础。未来,DeepSeek-V3将在AI领域发挥更加重要的作用,推动人工智能技术的进一步发展。



