在人工智能领域,多模态图像识别一直是研究的热点和难点。近期,开源项目VLM-R1成功将DeepSeek的R1方法从纯文本领域迁移到视觉语言领域,实现了多模态图像识别能力的新突破。该项目在GitHub上线后迅速获得广泛关注,登上热门趋势榜,为视觉语言模型的发展提供了新的方向。


VLM-R1的技术背景
VLM-R1的核心理念是将DeepSeek的R1方法应用于视觉语言模型(Visual Language Model, VLM)。R1方法最初是针对纯文本领域的优化技术,通过强化学习策略优化模型性能。VLM-R1在此基础上,结合了视觉和语言的多模态数据,使得模型能够同时处理图像和文本信息,从而提升图像识别的准确性和效率。

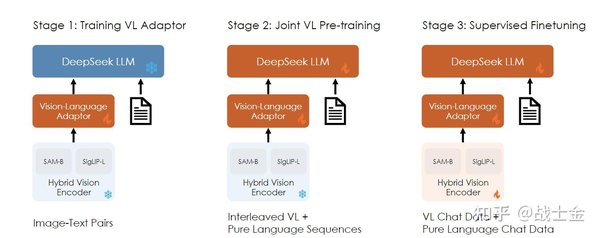
多模态图像识别的挑战
多模态图像识别涉及图像和文本的联合处理,其核心挑战在于如何有效地融合不同模态的信息。传统的单一模态模型在处理复杂场景时往往表现不佳,而多模态模型则能够通过结合视觉和语言信息,提供更全面的理解。然而,多模态模型的训练和优化难度较大,需要处理大量异构数据,并解决模态间的对齐问题。
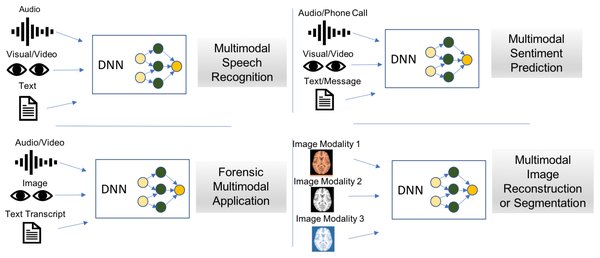

VLM-R1的创新之处
VLM-R1在以下几个方面实现了创新:
-
多模态数据融合:通过引入视觉语言模型,VLM-R1能够同时处理图像和文本信息,实现了多模态数据的有效融合。
-
强化学习优化:借鉴DeepSeek的R1方法,VLM-R1采用强化学习策略优化模型性能,提升了图像识别的准确性和效率。
-
开源社区支持:VLM-R1在GitHub上线后迅速获得广泛关注,吸引了大量开发者和研究者的参与,推动了项目的快速发展。
实际应用与前景
VLM-R1的成功应用为多模态图像识别领域带来了新的可能性。其潜在应用场景包括但不限于:
-
智能图像搜索:通过结合图像和文本信息,提升图像搜索的准确性和效率。
-
自动驾驶:利用多模态模型处理复杂的交通场景,提升自动驾驶系统的安全性和可靠性。
-
医疗影像分析:通过结合医学图像和文本描述,提升疾病诊断的准确性和效率。
结语
开源项目VLM-R1的成功标志着多模态图像识别领域的一次重要突破。通过将DeepSeek的R1方法迁移到视觉语言领域,VLM-R1为视觉语言模型的发展提供了新的方向。随着开源社区的持续支持和技术的不断进步,VLM-R1有望在更多实际应用场景中发挥重要作用,推动人工智能技术的进一步发展。




