引言
在大模型领域,长文本处理一直是一个技术难题。传统的模型由于记忆限制,难以处理超长上下文,导致信息丢失或错误结论。然而,清华大学和厦门大学等联合提出的LLMxMapReduce技术,通过创新的分帧处理方式,成功打破了大模型的记忆限制,实现了上下文长度的无限稳定拓展。
LLMxMapReduce技术的核心原理
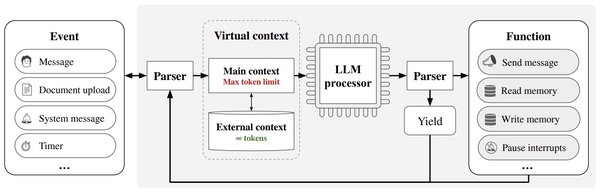
LLMxMapReduce技术借鉴了大数据领域中的MapReduce框架,采用“分而治之”的策略,将长上下文切分为多个片段,使模型能够并行处理这些片段,并从不同片段中提取关键信息,最终汇总成答案。这一技术的核心在于:
-
结构化通信协议:确保跨片段信息的高效处理。
-
上下文置信度校准机制:通过置信度评分,优先考虑高置信度的结果,提高最终答案的准确性。
技术优势与表现
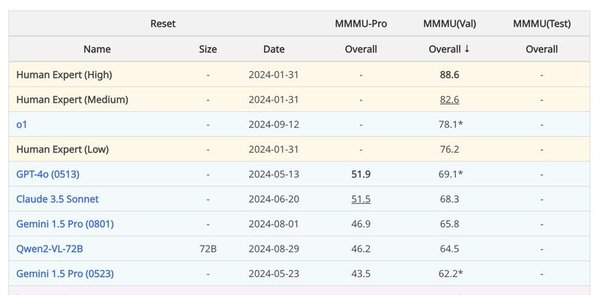
LLMxMapReduce技术在多个模型上表现出色,超越了包括Kimi和GPT-4在内的知名模型。具体表现如下:
-
无限长文本处理:通过LLMxMapReduce技术,MiniCPM 3.0实现了无限长度的文本处理能力,上下文长度从32K、128K拓展至512K甚至更高。
-
性能提升:在权威评测集InfiniteBench上,结合LLMxMapReduce框架的Llama3-70B-Instruct模型得分超越了Kimi、GPT-4等知名模型。
-
通用性强:该技术不仅适用于Llama3-70B-Instruct,还结合Qwen2-72B和MiniCPM3等模型取得了优异成绩。
应用场景与未来展望
LLMxMapReduce技术的应用场景广泛,包括但不限于:
-
学术研究:一次性处理整本书籍或海量学术论文,提升研究效率。
-
智能助手:记住跨越多年的聊天记录,成为最懂用户的AI陪伴者。
-
智能体应用:通过Function Calling功能,调用端上的各种工具和函数,扩展模型的应用边界。
未来,随着端侧AI技术的不断发展,LLMxMapReduce技术将在更多领域展现其潜力,推动大模型技术的进一步革新。
结语
LLMxMapReduce技术的提出,不仅解决了大模型长文本处理的难题,更为端侧AI的发展开辟了新的道路。这一技术的成功应用,标志着大模型技术进入了一个新的纪元,未来将带来更多令人期待的应用和突破。





