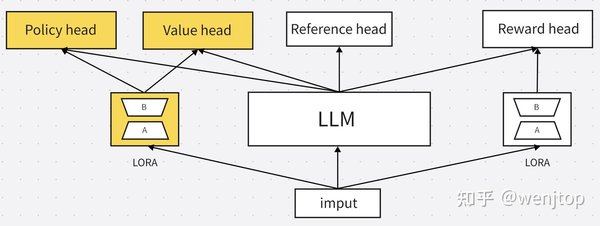
GRPO算法的背景与核心原理
GRPO(Generalized Reinforcement Policy Optimization)算法是PPO(Proximal Policy Optimization)的改进版本,旨在通过采样原理简化value model,从而提升训练的稳定性和可维护性。该算法在DeepSeek-R1模型中得到了广泛应用,并在海外科技界引起了广泛关注。
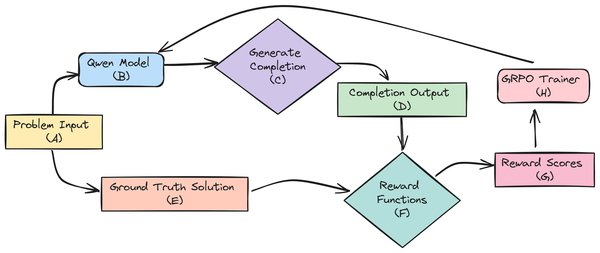
GRPO在DeepSeek-R1中的应用
DeepSeek-R1模型通过GRPO算法在强化学习中取得了显著成效。具体来说,GRPO算法通过多实例数据并行采样和异步采样等技术,显著提升了训练速度。例如,在8卡训练中,配置4张卡负责模型训练,4张卡负责采样,训练时长可缩短至1卡采样的87%。
技术优化点
- 多实例数据并行采样:通过合理分配训练和采样资源,降低采样耗时。
- 异步采样:在训练时同时进行采样,采样结果用于下一轮模型训练,进一步缩短训练时间。
- 多轮更新:通过设置参数num_iterations,多次利用采样数据,缓解采样过程对训练速度的影响。
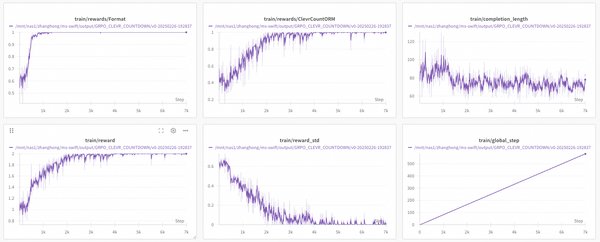
GRPO在多模态训练中的突破
GRPO算法在多模态训练中也展现出了强大的潜力。通过支持图文、视频、音频等多模态内容的输入,GRPO在多模态计数任务上进行了训练,并取得了显著成效。例如,在CLEVR-70k-Counting数据集上,模型训练了500个epoch后,任务成功率从初始的0.4攀升到1左右。
GRPO在推理效率优化中的表现
GRPO算法在推理效率优化方面也取得了突破性进展。通过元强化微调(MRT)方法,GRPO在多个基准测试上取得了SOTA结果。例如,在AIME 2024数据集上,MRT的准确率比基础模型高出5%,且所需token数量比基础模型少5倍。
MRT方法的优势
- token效率提升:MRT在保持或提升准确率的同时,显著提高了token效率。
- 进展奖励:通过衡量生成给定片段前后获得正确答案的似然变化,MRT为RL训练规定了密集的奖励。
GRPO算法的未来展望
GRPO算法在AI领域的应用前景广阔。未来,随着模型规模的扩大和计算资源的增加,GRPO算法有望在更多复杂任务中展现其优势。例如,在编程、数学问题求解和科学推理等领域,GRPO算法有望推动AI系统实现更高效的结构化推理和逻辑验证。
总结
GRPO算法作为强化学习领域的重要创新,通过优化采样和训练流程,显著提升了AI模型的训练效率和推理能力。其在DeepSeek-R1模型和多模态训练中的成功应用,为AI技术的发展提供了新的思路和方向。未来,随着技术的不断进步,GRPO算法有望在更多领域发挥其潜力,推动AI技术的广泛应用。





